







 智算多多
智算多多联系我们


关注我们

公众号

视频号
隐私协议用户协议
◎ 2025 北京智算多多科技有限公司版权所有京ICP备 2025150592号-1
1.架构分歧:超节点的两种架构路线
业界在超节点架构上的分歧,集中于“SuperPod”与“SuperNode”的路径选择。二者之名表面差异的背后,是系统设计理念的根本不同。这一分歧将深刻影响系统可靠性、可扩展性及工程实践等核心维度。
(一)SuperPod-分布式集群
SuperPoD架构的本质是: 由多台相对独立的GPU服务器通过高速网络互联构成的可扩展集群,这其实就是SUN公司在1984年提出的Network is Computer(网络就是计算机)的理念(AI 基础设施迈入百万卡时代:重燃 “网络即算力” 革命)。
行业领导者最新发布的超节点产品和路标,比如华为今年在世界人工智能大会发布的CloudMatrix384(注:当然也存在改进空间,具体见 针对华为CloudMatrix384超节点的个人看法)和在华为全联接大会上发布的Atlas 950/960/850(如下图),以及AMD 预计2027年发布的 MI500 UAL256 (炸裂新闻:AMD 入局!开放解构超节点技术阵营再添重量级成员),均采用了SuperPod架构。
这里顺便提一下Atlas 850(注:华为称之为业界首个企业级风冷AI超节点服务器),支持风冷是非常务实的选择。今年初,我提出风冷开放解构超节点的设想 (开放解构架构智算超节点,破土而出),一些人认为这根本不能算不上是超节点,理由是“没有液冷就称不上超节点”,”不是整机柜就称不上超节点“。有这种想法的人通常是没有很好地运用马斯克经常提到的”第一性原理“来深度剖析超节点的本质,而是被NVL72表象所迷惑并盲目跟风。若觉得“第一性原理”抽象,不好应用,也不妨运用“多、快、好、省”这个普适的标准来检验一下:1)“多”:能否连接更多的GPU以构建更大规模的HBD(高带宽域);2)“快”:能否实现GPU之间的高速通信;3)“好”:注意,不是“优”,不追求极致完美,而是需在投入和产出上、极致性能和快速商业落上等方面取得平衡,这其实就是good enough工程设计原则;4)“省”:能否以更少的投入、更低的成本实现并部署。


保持每个计算节点的独立性,即每个计算节点均包含配套的CPU、GPU及内存,自成完整的服务器单元,通过网络互联构成一个逻辑上的“超级计算机”,该技术路线的最大优势在于极强的鲁棒性和良好的可扩展性:单一计算节点的故障不影响整个超节点系统继续运行,符合大规模分布式系统鲁棒性设计原则,有效保障了业务连续性;同时,“通过Scale-out 的方式构建 Scale-up 网络,即以开放解耦的方式取代封闭耦合的方式,构建高带宽域(HBD)网络,实现了真正意义上的开放超节点系统架构”(具体见Scale-up 网络技术路线与超节点硬件系统架构探讨)。这里有人可能质疑:Scale-up网络怎么搞起了Scale-out(水平扩展),这是典型的“形而上学”思维定式,“不管白猫黑猫,抓住老鼠就是好猫”这句话同样适用于技术架构设计。
(二)SuperNode-刀片服务器模式
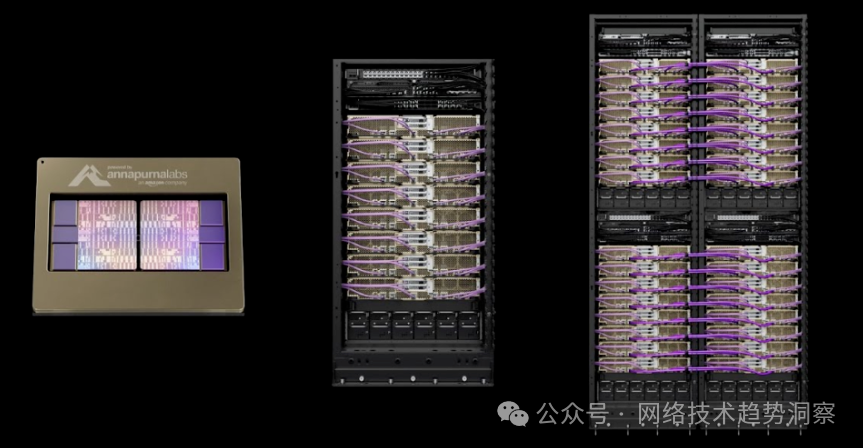
如上图所示,AWS Trainium2 的服务器架构(即上图居中的设备,其采用刀片服务器的设计架构,CPU和GPU分别部署在不同的Tray,并依赖外部AEC线缆互联构成一台16卡GPU服务器),国内外的一些厂商,“照猫画虎”,造了一个更大卡数(比如64卡或128卡,具体哪家就不点明了)的刀片服务器。这种SuperNode的技术路线,将CPU与GPU在物理上解耦,好处是CPU与GPU灵活配比,不足之处是系统的故障爆炸半径较大,且无法像开放解构超节点那样实现“可拆可合”的灵活配置方式(具体见开放解构超节点:AI基础设施的“变形金刚”)。
2.认知鸿沟:架构分歧的深层原因
超节点领域目前出现的技术方案参差不齐的现象,根源在于对其本质属性的理解偏差与计算与网络专业协同的缺失。一方面,存在本质认知偏差,即误将超节点看作更大规模服务器,忽视了网络在超节点系统的核心和重要价值,没有理解Network is Computer(网络就是计算机)的含义;另一方面,计算与网络专业协同不足,计党完全主导的超节点设计,往往对于“互联互通”的重要性认识不足,采取“烟囱化”设计理念,结果就导致各GPU厂商开发私有互联技术,各种所谓XX-LINK协议满天飞,造成生态碎片化,无形中提高了行业应用成本与客户技术选型难度,其中XX芯X800就是一个典型的案例,由于在网络层面考虑的不足,导致无法完全兼容标准的以太网(注:每个GPU只有一个400G Scale-Up接口可以与标准以太网兼容),必须依赖可编程的以太网芯片比如TD5来进行特殊处理,识别特殊的报文字段进行寻址转发。
3.破局之道:以开放解构实现价值回归

当前超节点技术讨论热度空前,但是商业落地则是屈指可数。究其原因,还是由于超节点技术标准缺失,各家厂商方案参差不齐,协议私有,硬件系统封闭,厂商锁定风险极高,导致客户难于决策,普遍处于观望状态。在行业标准成熟之前,“开放解构”理念是平衡技术合理性、客户部署灵活性和投资保护的最优路径。其核心在于通过“可拆可合”的架构设计,最大化系统适应性,既能整合为超节点应对大规模训练和推理场景需求,也能拆分为独立服务器来使用务,从而降低客户决策风险并实现投资保护。
4.结论与展望
超节点的未来属于以SuperPod为代表的、秉承分布式系统理念的开放解构架构。行业领导者们的共同选择已清晰指明了技术方向。
推动行业成熟需要完成两个关键转变:一是认知转变,彻底摒弃“重计算、轻网络”的传统观念,建立超节点依赖计算和网络深度协同的系统工程思维;二是路径转变,从封闭私有技术路线走向开放解构、标准驱动的开放技术路线。对于那些坚持私有封闭技术路线的GPU厂商,特别是那些不具备行业垄断地位的中小厂商而言,需清醒认识到“蚂蚁战大象”的战略意义,唯有融入开放生态,才能真正赢得未来。
本文转载自「微信公众号:网络技术趋势洞察」,原文链接:https://mp.weixin.qq.com/s/Uzy4-So0Q4fhq9O6zFv7Tg。转载仅为分享交流,不用于商业用途,版权归原作者及原平台所有。若有侵权,请联系我们,我们将第一时间删除处理。
智算多多