
 智算多多
智算多多联系我们

官方邮箱:service@zsdodo.com

公司地址:北京市丰台区南四环西路188号总部基地三区国联股份数字经济总部
关注我们

公众号

视频号
◎2025 北京智算多多科技有限公司版权所有 京ICP备 2025150592号-1
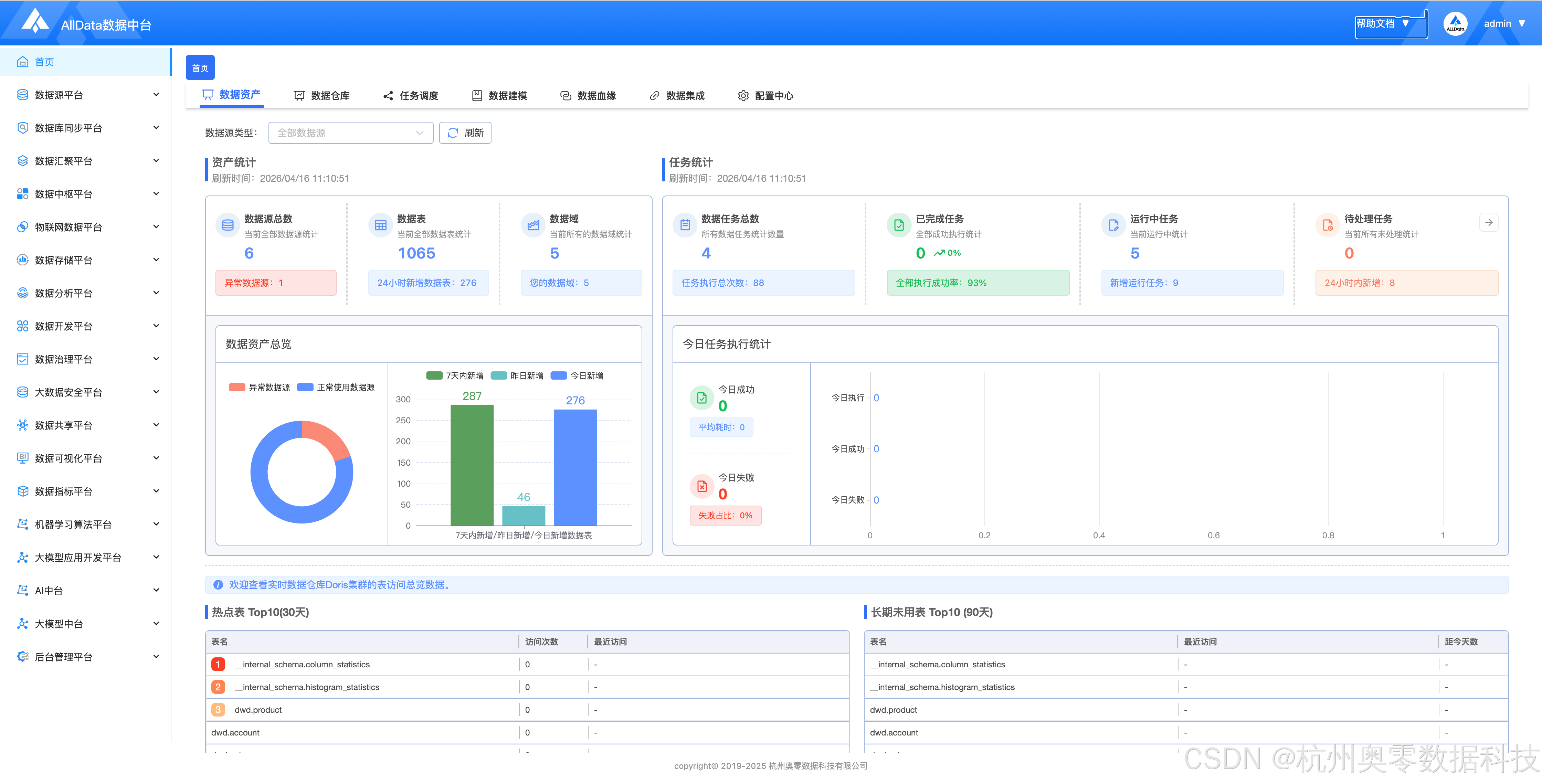
● 业务数据散在 MySQL、Doris、日志、IoT,孤岛林立,没法直接喂模型
● 人工标注慢、成本高、质量参差不齐,百万条数据要数月,还容易出错
● 合成数据缺标准、缺工具、缺流程,脚本满天飞、 pipeline 不可复用、效果不可控
● 传统数据中台只管 “存、洗、算”,没有大模型数据生成能力,AI 和数据两张皮
● 支持HIS、LIS、PACS、EMR医疗行业数据接入
● 支持PLM, ERP, MES等工业制造信息系统数据接入
● 支持非结构化数据:办公文档、文本、图片、各类报表、图像、音频、视频
数据质量决定模型上限 —— 没有高质量、规模化、领域对齐的训练 / 微调数据,再强的大模型也跑不出业务价值。
我们基于开源项目 DataFlow 框架深度集成,把 “数据中台底座 + 大模型数据工厂” 合二为一,一站式搞定从业务数据接入→合成→治理→评估→模型应用全链路,零代码 / 低代码,开箱即用,实现高效生产大模型训练数据的高质量数据集平台。

DataFlow 核心定位是以数据为中心的 AI 基础设施,专为大模型训练与 RAG 场景打造,解决数据处理碎片化、复现难的问题。
在 AllData 数据中台内,DataFlow 负责数据集构建与治理,提供算子库、Text2SQL 数据集切换、大模型服务 / 数据库管理等能力,端到端保障高质量数据输入,提升大模型应用效果与项目交付效率。

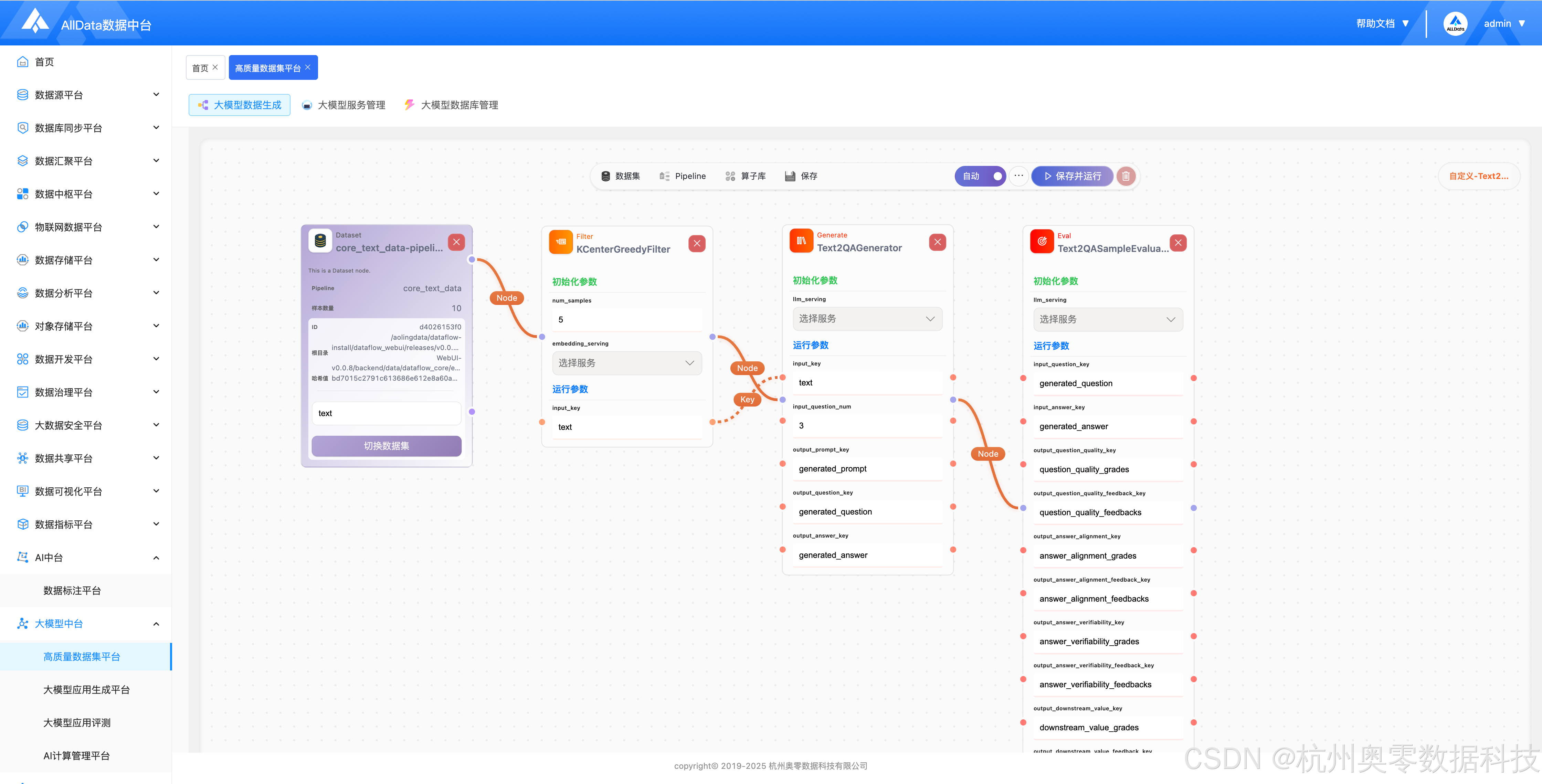
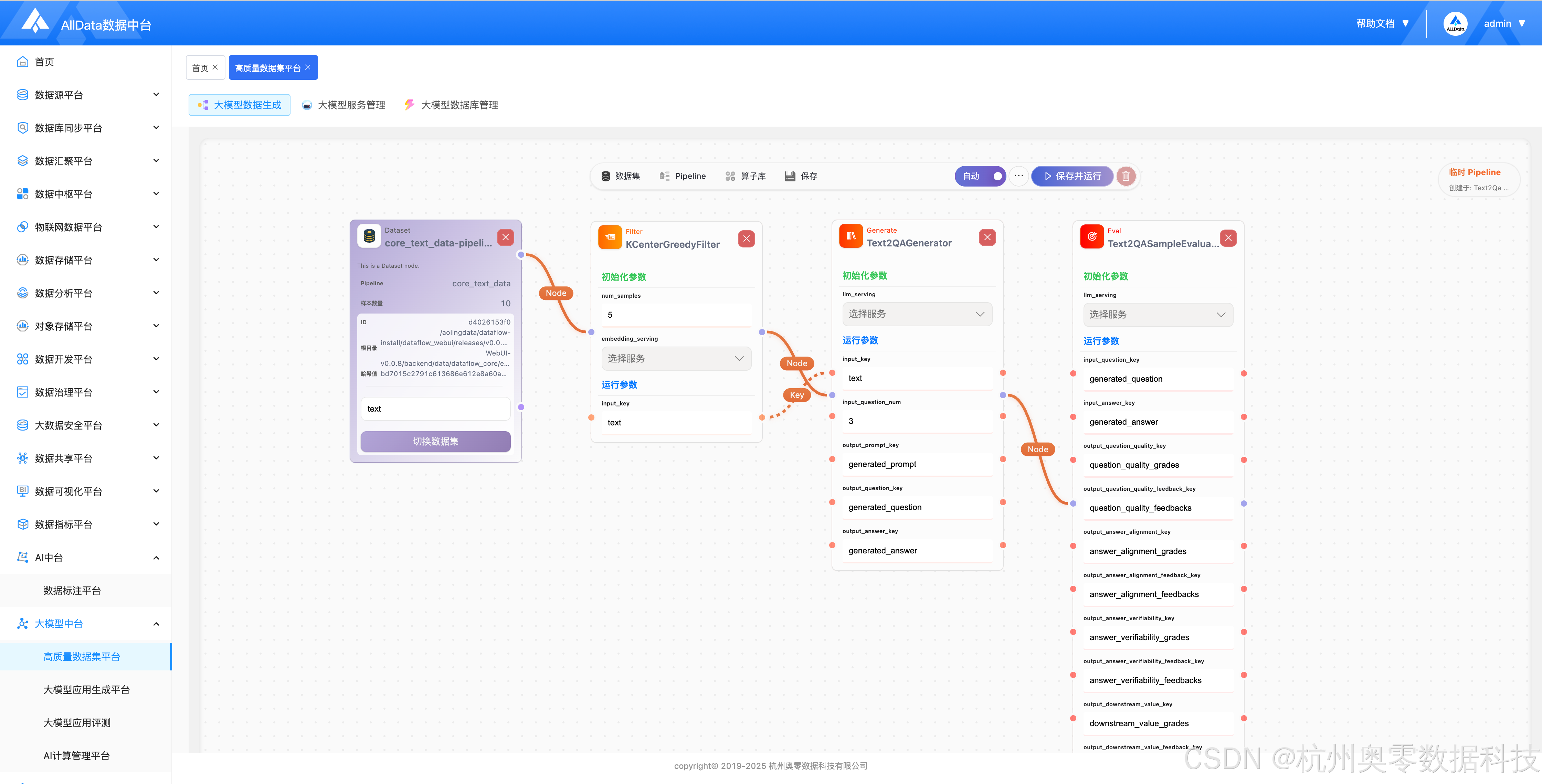
提供可视化拖拽编排,支持从多源数据清洗、增强、合成到过滤、去重、标注的全链路自动化 Pipeline,可批量生成高质量 SFT/RLHF 训练集、Text-to-SQL、问答对、推理数据,一键导出合规数据集,大幅降低大模型数据生产门槛与成本。
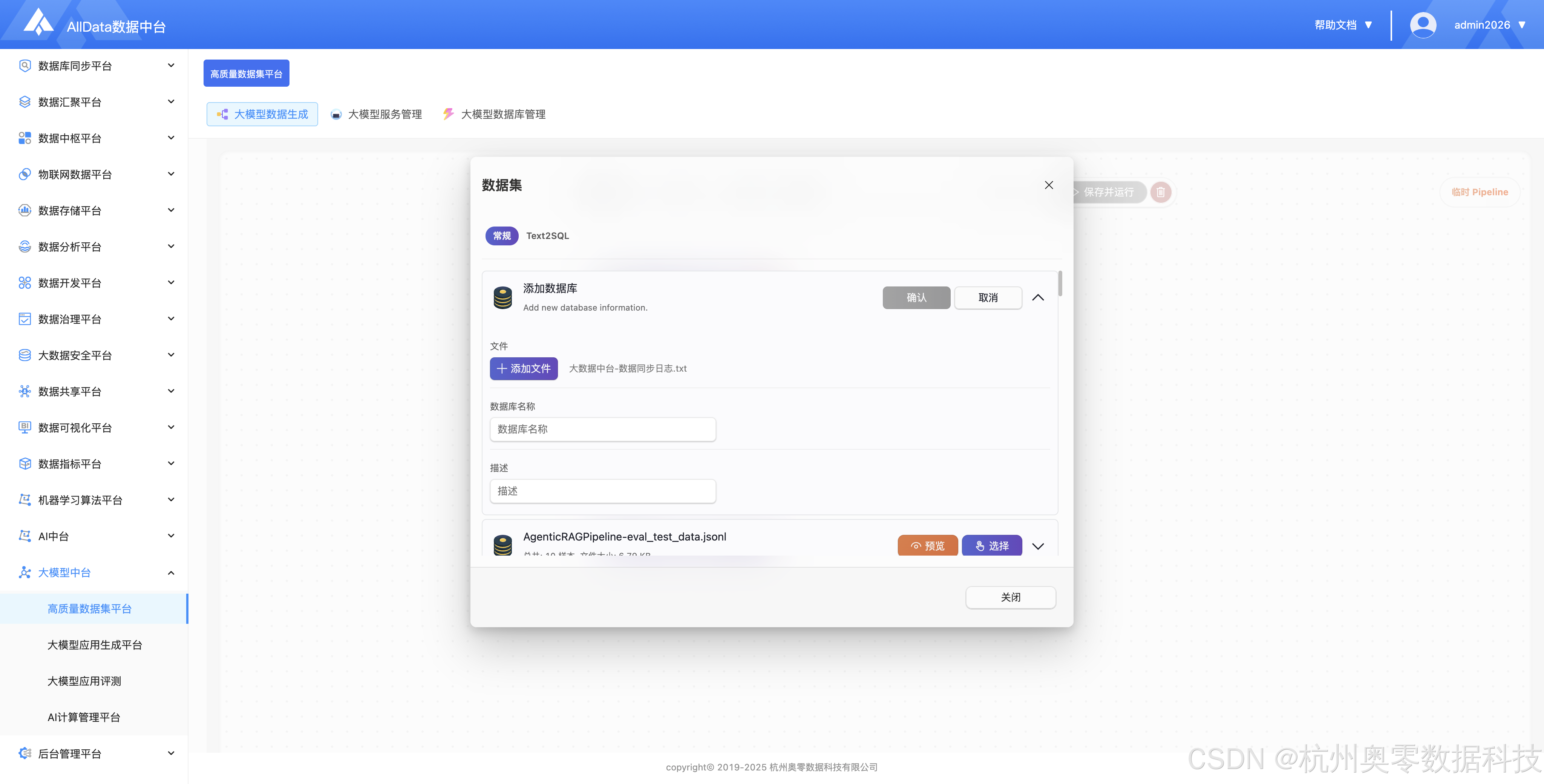
支持通用场景数据集快速创建与编辑,可对文本、问答等基础数据进行导入、预览、筛选与导出,满足日常大模型训练数据标准化管理需求。
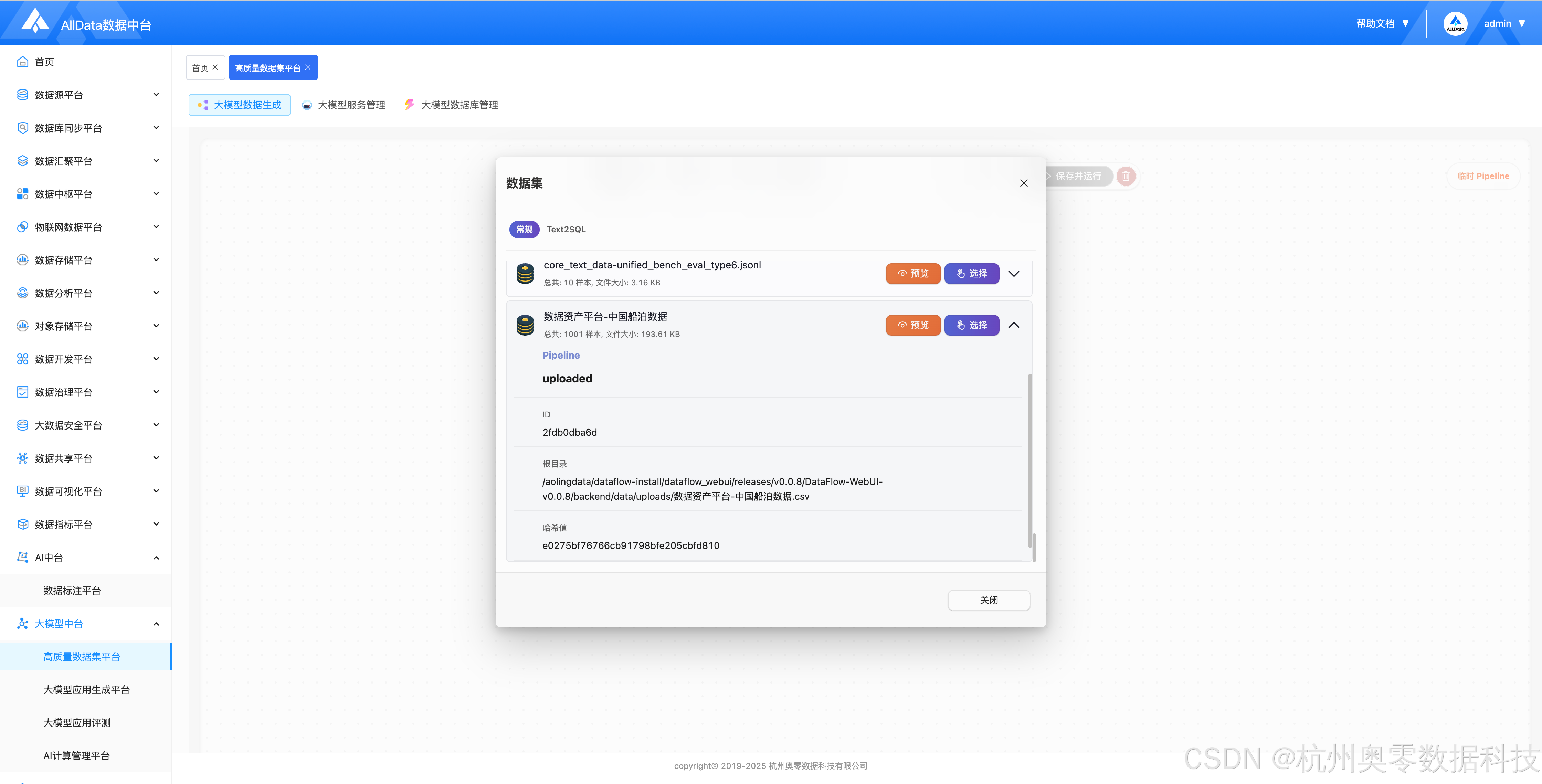
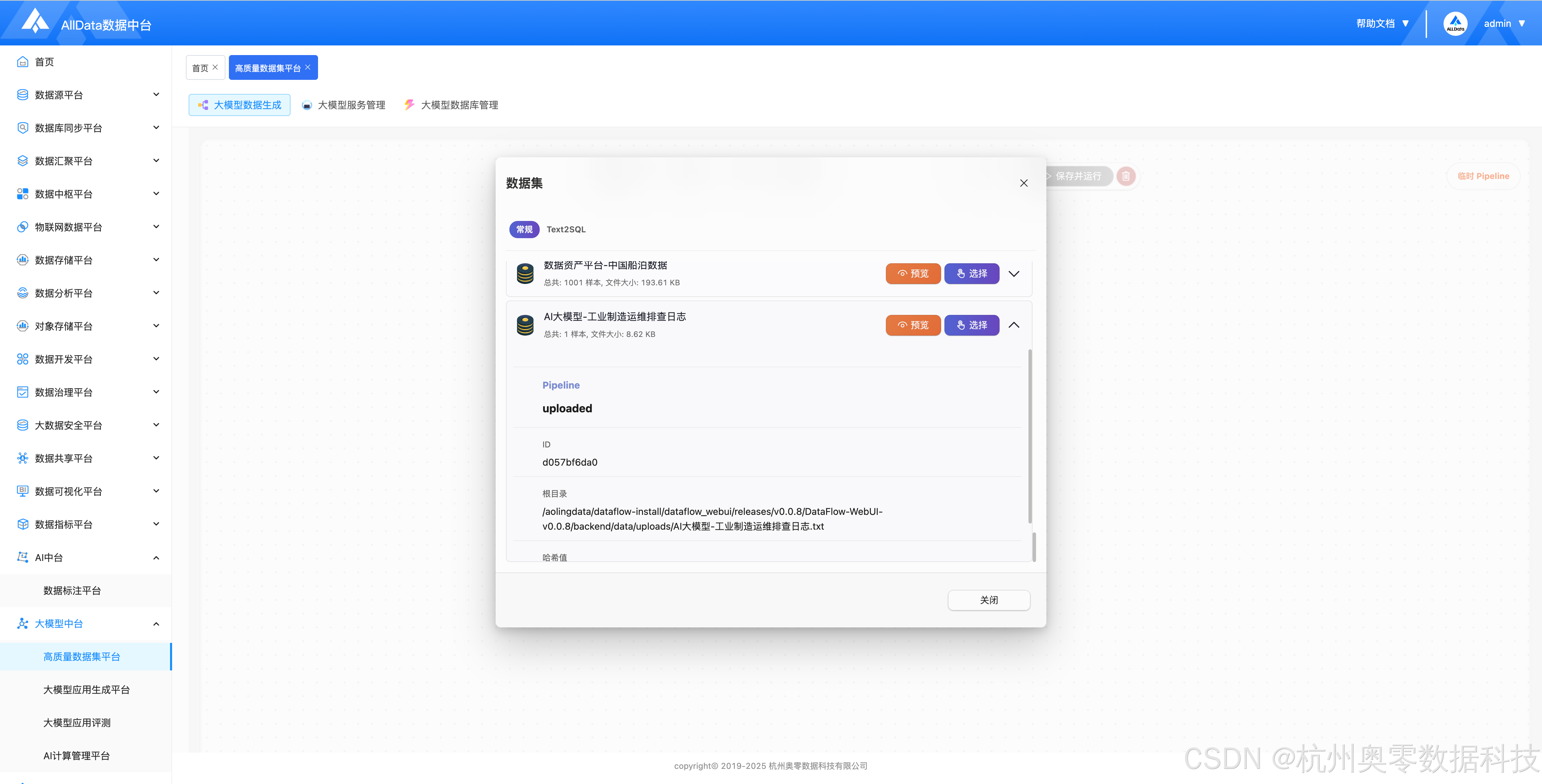
面向 Text2SQL 场景专项构建数据集,支持自然语言问句与 SQL 语句自动配对生成、校验及标注,为模型训练提供高质量语义查询数据集。
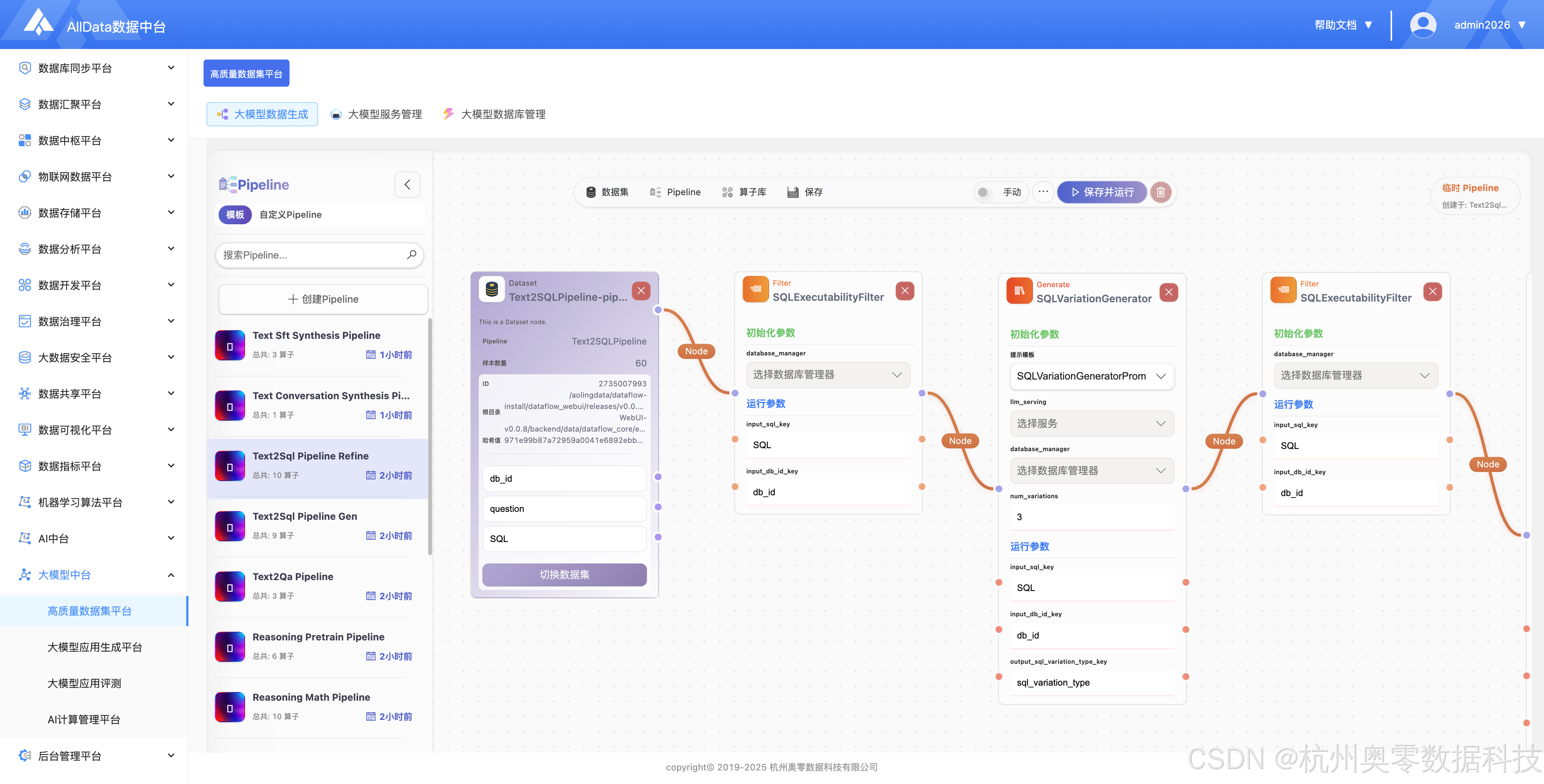
通过可视化编排自动化任务,实现数据集批量生成、处理与全流程智能执行。
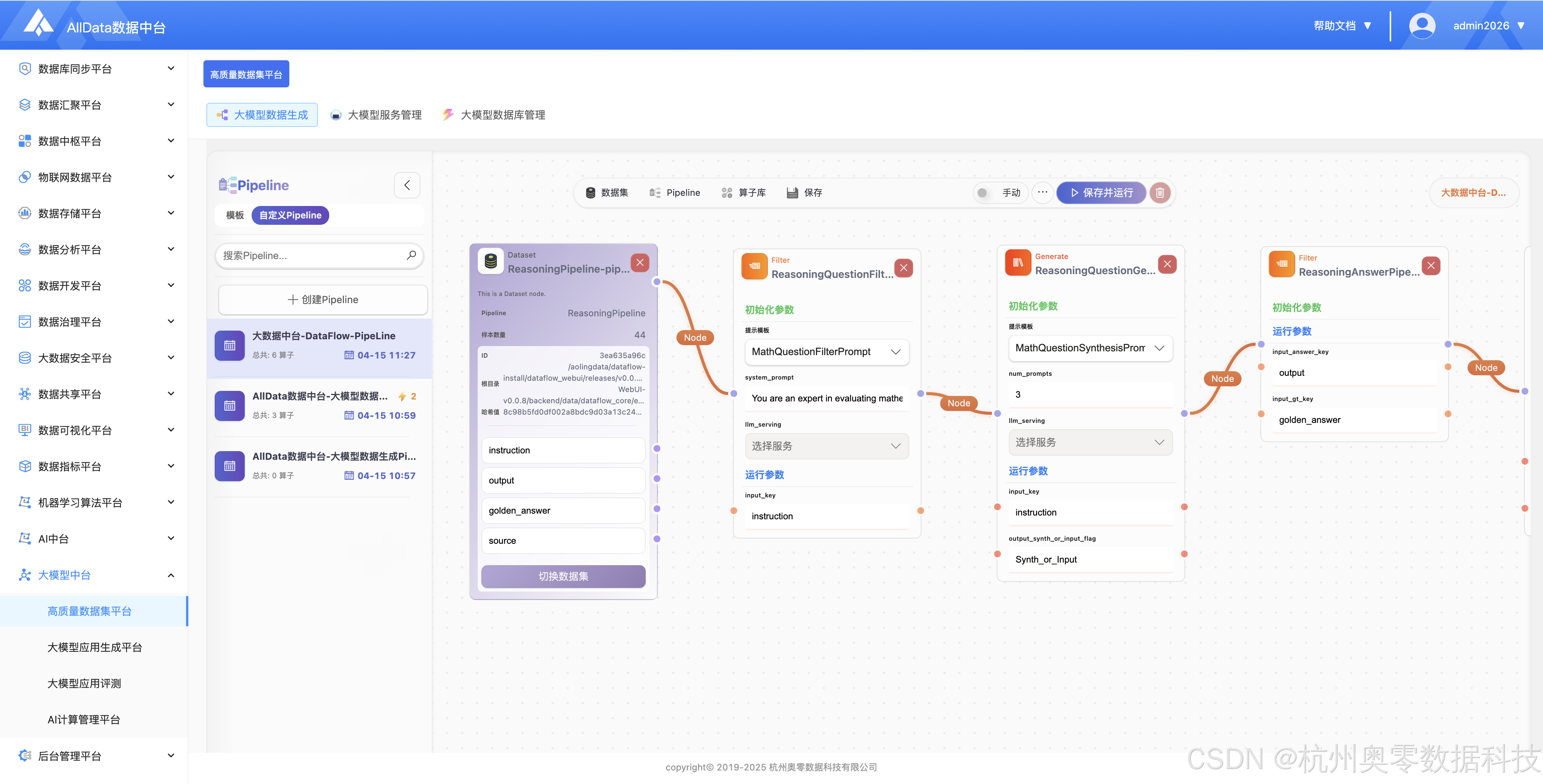

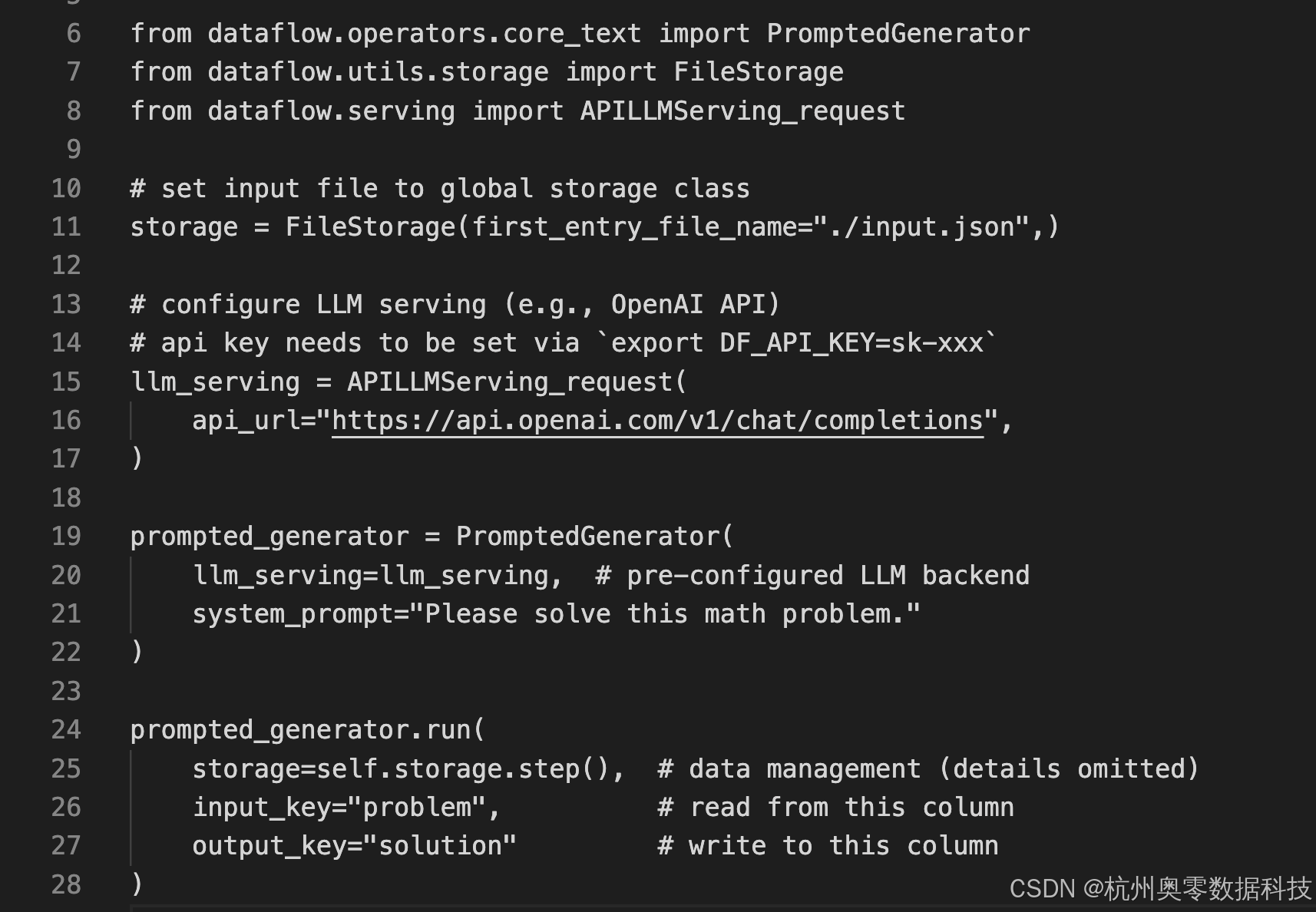

支持在大模型高质量数据集间快速切换,方便对不同通用数据集进行编辑与生成操作。
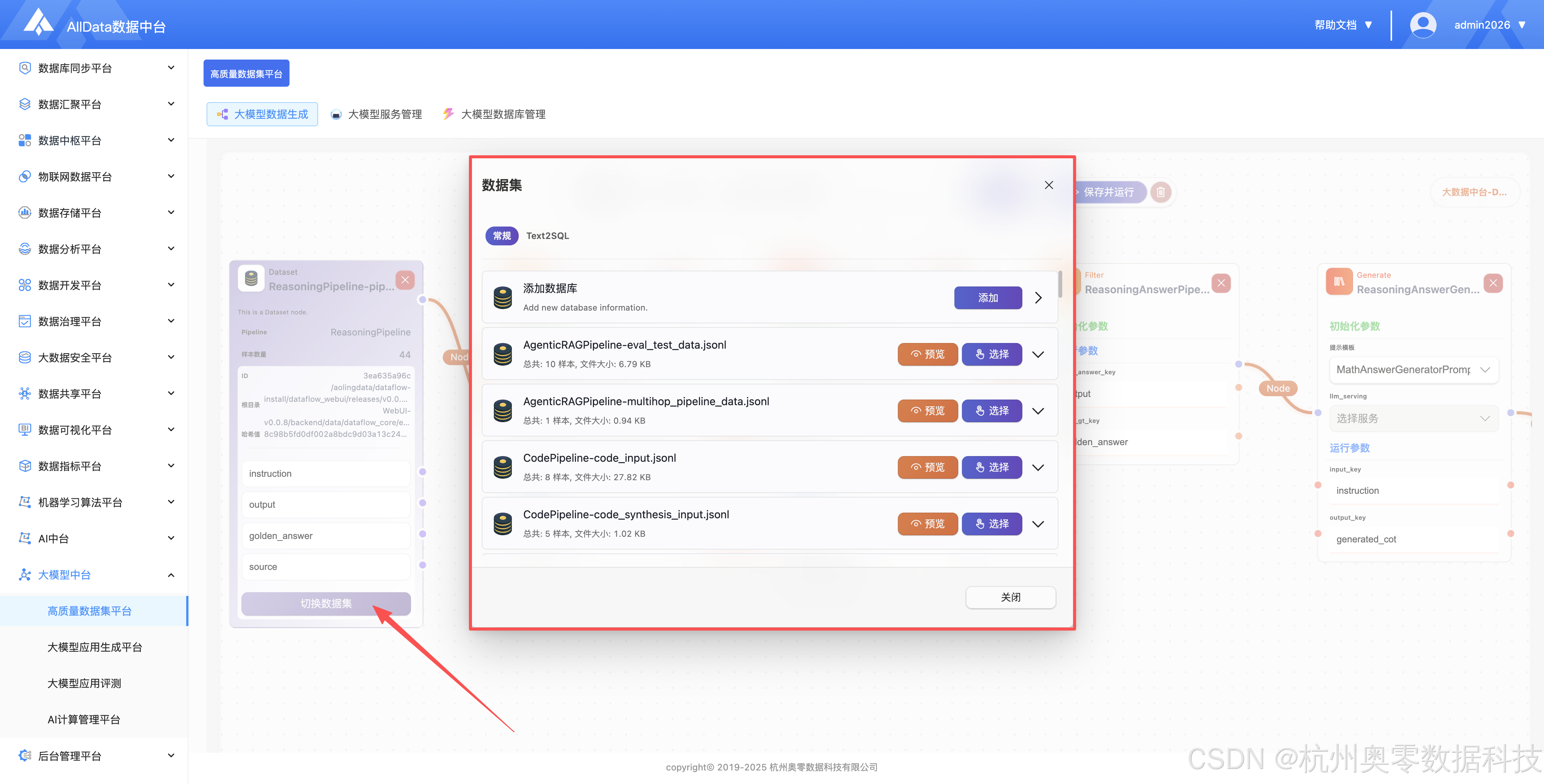
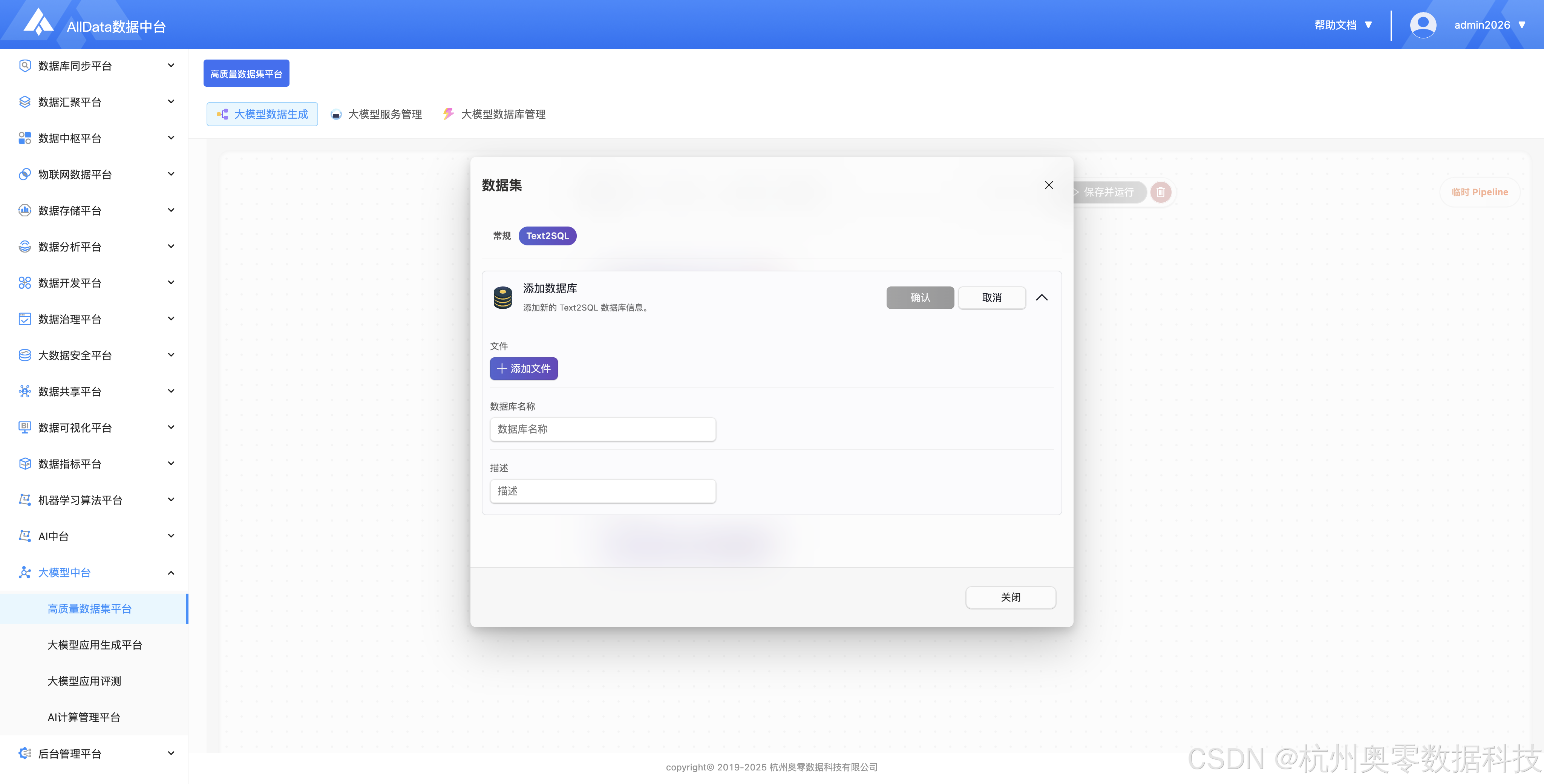
支持快速切换 Text2SQL 专用数据集,便捷开展问句与 SQL 配对数据管理。
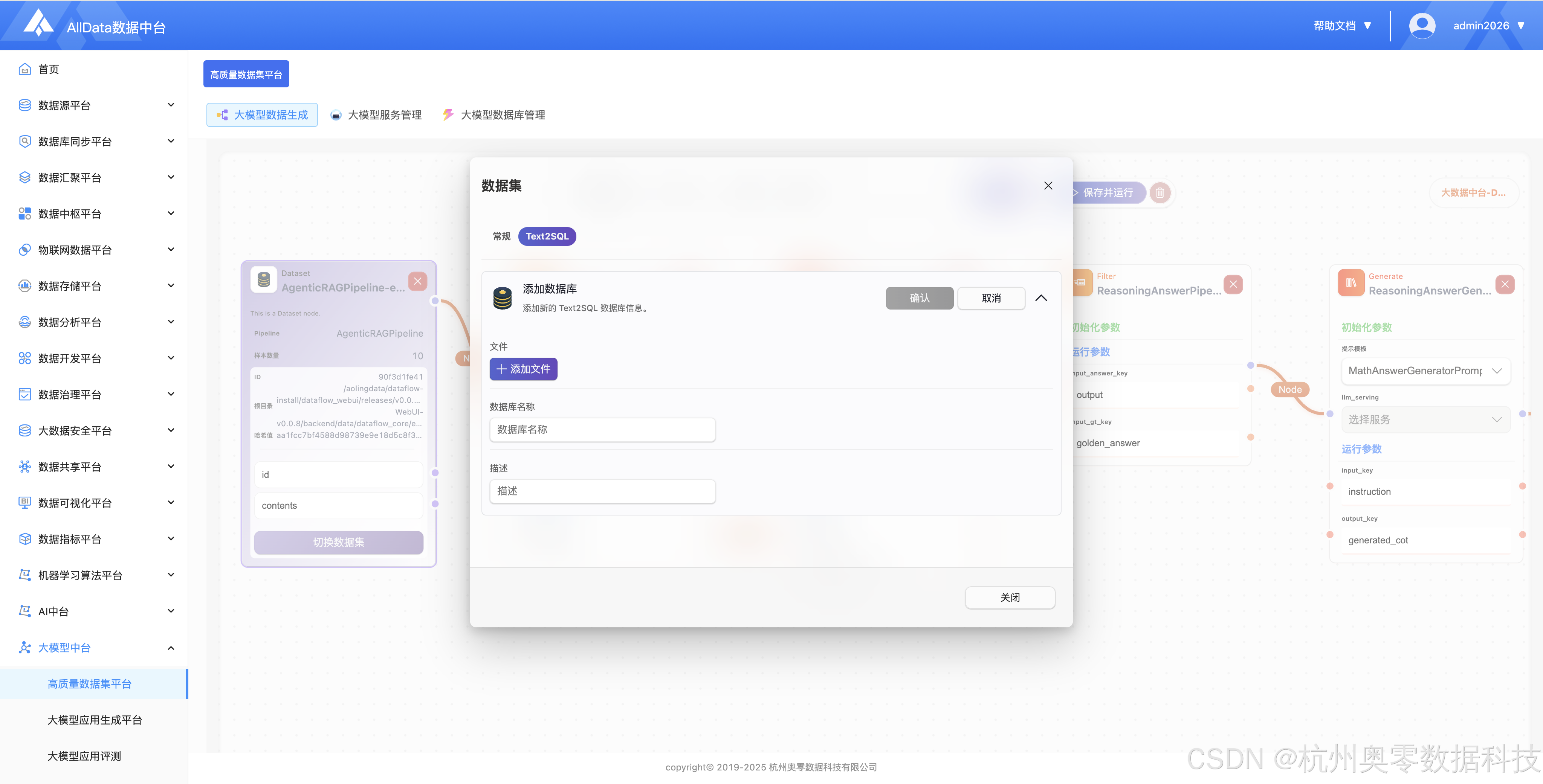
提供196+丰富的数据处理算子,支持拖拽组合,实现数据清洗、增强与生成流程编排。
统一管理大模型接入配置、密钥与调用权限,保障 AI 服务稳定可靠运行
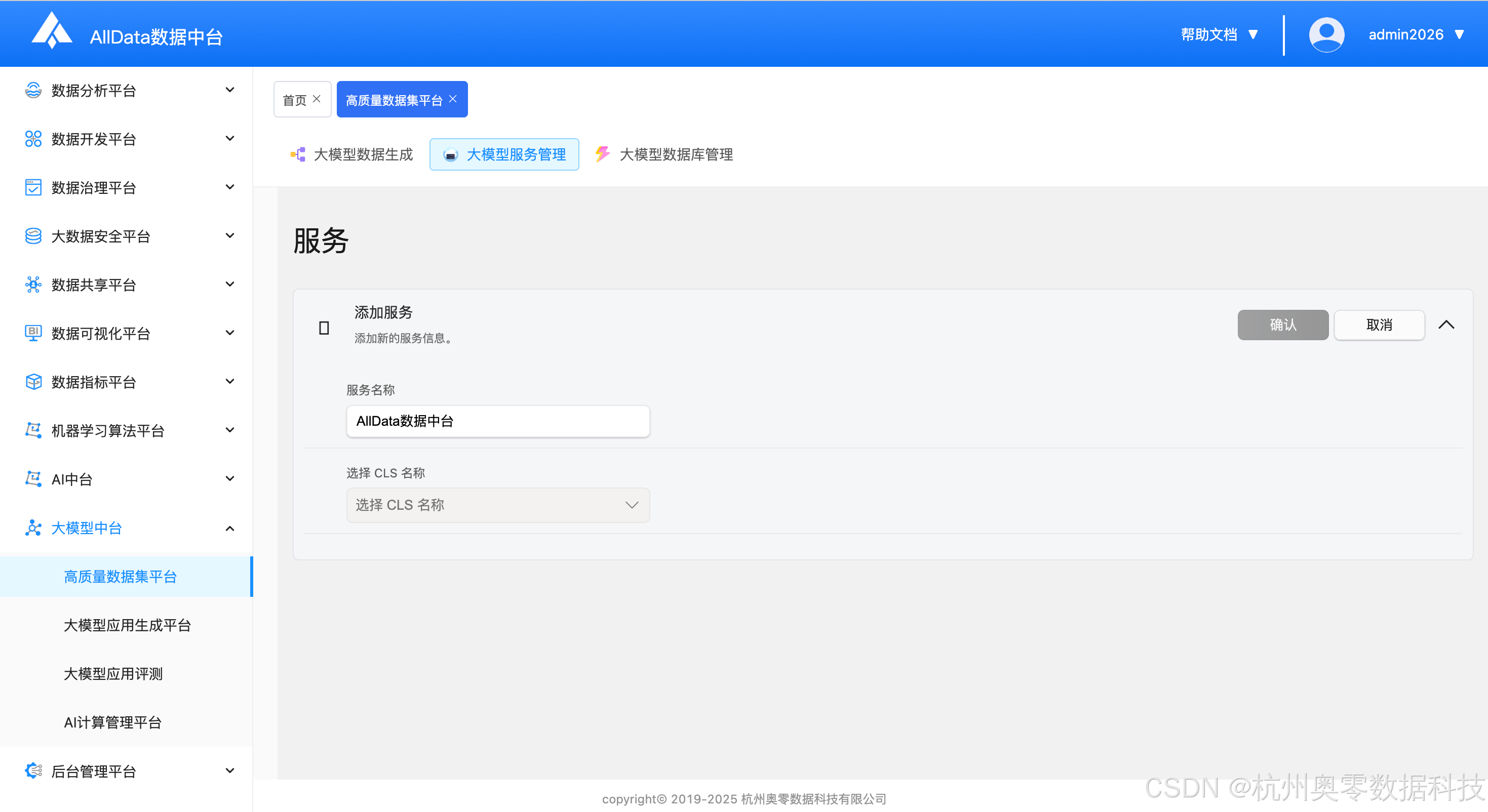
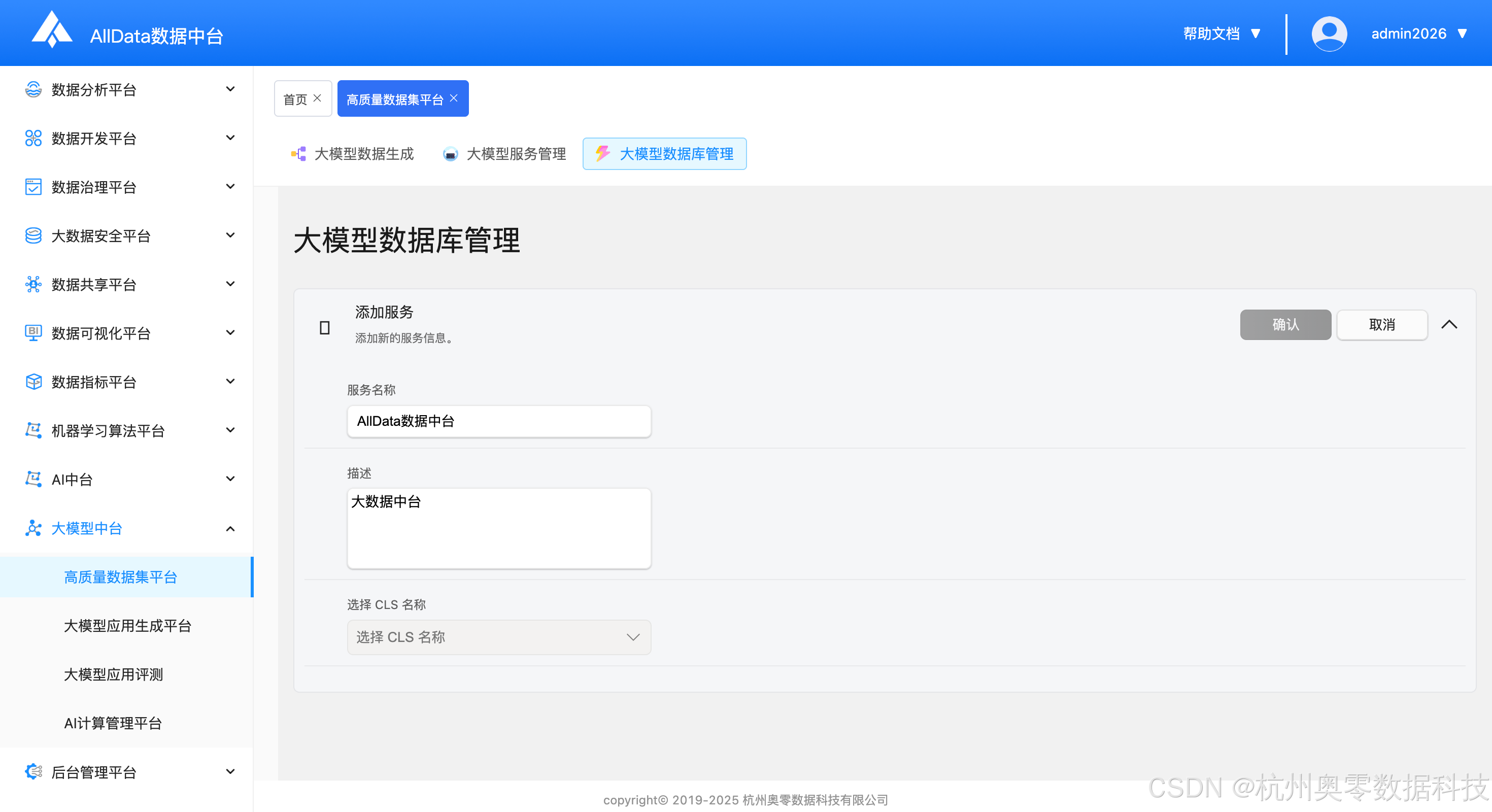
统一管理向量库与业务数据库,支持连接配置、数据存储及高效检索服务。

 智算多多
智算多多官方邮箱:service@zsdodo.com
公司地址:北京市丰台区南四环西路188号总部基地三区国联股份数字经济总部