







 智算多多
智算多多联系我们


关注我们

公众号

视频号
隐私协议用户协议
◎ 2025 北京智算多多科技有限公司版权所有京ICP备 2025150592号-1
建立大模型的首要步骤是明晰任务类型,若是以模型预训练当作目标,就要着重于高算力硬件,要是仅仅用于推理或者微调,那么对于延迟以及并发能力的要求就更高。常见的应用场景涵盖智能客服、代码生成、文本摘要等,不同的场景对于模型参数量、上下文长度以及生成速度有着非常明显的差异。比如,面向代码补全的模型需要起码8192 token的上下文窗口,而智能问答系统则要求首Token延迟低于500毫秒。如按照预估的并发用户数,也就是100人同时进行使用的情况,推理端必须配置充足的显存以及网络带宽。

K1X1 4090(具备4GB亚存)能够满足推理所需,然而0/1亿参数的混合专家模型(比如-V3,其总参数为671B,激活参数为37B)则至少需要4张RTX 4090(总计96GB显存)或者2张A100 80GB。训练具备700亿参数的模型之际,典型的配置是8张 A100 80GB GPU,这8张GPU搭配2颗Intel Xeon 8488C处理器,这2颗处理器一共有56个核心,还配备有512GB DDR5内存以及4TB NVMe固态硬盘。在国产化的场景当中,可以选用华为昇腾910B,它的FP16算力是320,单卡显存为64GB,8卡互联的情况下能够训练千亿级别的模型。网络这一块,训练集群要配置那种的或者RoCE网络,目的在于把参数同步时产生的延迟给降低。
当下主流的开源大模型涵盖了-V3、Qwen2.5-72B、LLaMA-3-70B等,-V3运用MoE架构,其总参数是671B,激活参数为37B,训练消耗达到278万H800 GPU ☎小时,Qwen2.5-72B属于密集模型,进行推理至少需要140GB显存(能够使用4张RTX 4090),在框架方面,2.3搭配或者-LM能够达成模型并行训练。在进行微调这一特定场景区间之内,LoRA这样一种方法能够把显存所占用的量降低到原本模型的百分之三十。针对于量化推理这种情况而言,AWQ或者GPTQ算法可以把模型权重压缩成为4-bit,并且精度方面的损失被控制在百分之一以内。
训练的高质量数据要达到万亿字符的级别才行,就拿训练130亿参数模型来说,至少得有1.2万亿token☐的文本数据,数据来源涵盖公开语料,像The Pile数据集,它包含825GB文本,还有行业文档以及内部知识库,预处理流程有去重,采用算法,相似度阈值设为0.7,接着清洗,要过滤那些非自然语言字符,再进行分词,采用Byte Pair,词表大小是32000,最后进行隐私脱敏,通过正则匹配手机号、身份证号。更新呈现增量状态的场景之时,要去设计那种向量数据库,就好比是这样的,用来支撑每日都会增加的文档能够进行实时索引,切片的长度给出的建议是512个token,重叠的比率是10%。
假设处于预训练时期,拿着着700亿参数的模型当作例子,是在1024张那种A100 80GB规格的GPU上开展训练的,训练1.8万亿token大约需要54天时间,其总的计算量大概是2.1e24 FLOPs。开展训练的时候需要去配置学习率预热,也就是在前3750步的时候要从0开始线性增长直至3e-4,又需具备余弦衰减的特性以及梯度裁剪,梯度裁剪的最大范数设定为1.0。每一次保存检查点的时候都要消耗15分钟时间,并且会占用2.8TB的存储。进行微调的阶段之时,运用的是100万条指令数据,于8张A100之上开展训练,历经3个epoch大约需要72小时,把学习率设定为2e-5,批次大小为128。在监督微调过后,能够进一步去采用直接偏好优化即DPO,不需要奖励模型便可以达成人类偏好的对齐,训练数据要求包含5万对“选中-拒绝”样本。
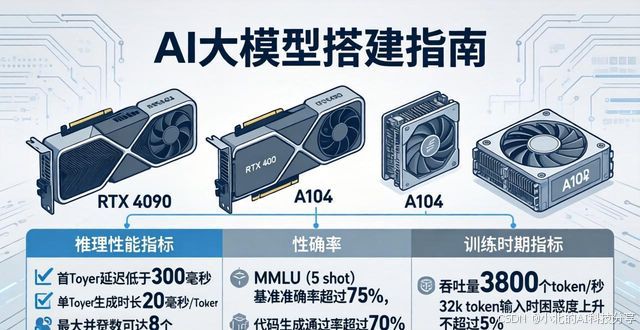
对其进行评估的时候,是需要涵盖多个不同维度的。其中,推理性能方面的指标包含有:首Token延迟,这个需要低于300毫秒;单Token生成时长,20毫秒/Token才算是合格的;最大并发数,单卡RTX 4090运行70B量化模型的时候能够达到8个并发。而准确率指标运用的是MMLU(5 shot)基准,70B模型应当要达到75%以上,且代码生成♡通过率需要超过70%。培训时期留意吞吐量,其典型数值是每张A100于每秒之际处理3800个token(模型规模为70B)。上下文长度的测试要去证实,模型在32k token输入之时,困惑度的上升幅度不超过5%。
部署方式能够选择本地一体机,要不然可以选云服务器。要是在本地进行部署的话,就得考虑功耗这方面的问题,还有散热,4张RTX 4090在满载的情况下功耗大概是1800瓦,还得配置4U机箱以及水冷系统。推理优化技术涵盖这些:1)存在连续批处理这种情况(吞吐量 Q 能够提升3至5倍);2)有-2(注意力计算速度提高2倍,显存占用会减半);3)包含张量并行(多卡之间的通信延迟需要低于10微秒)。定量规划提议W4A16(权重为4位,激活为16位),能够让70B模型的显存占用从140GB下降到35GB。针对实时性需求高的情形,可以部署vLLM框架,其技术能够把键值缓存内存碎片降低到1%以下。
有关数据安全这一方面,给出这样的建议,关键的部门要独立布置那种有着物理隔离的一体机。对于访问控制而言,要去施行基于角色的权限管理也就是RBAC,在最小权限的原则之下,普通的用户仅仅能够调用预先设置好的API,只有管理员才有资格去访问训练数据。全部的操作日志都需要留存最少180天,并且要定期去审计异常的调用情况比如同一IP在单日的请求超过5000次。模型输出要配置内容过滤层,依据敏感词库包含2000个禁用词汇以及正则规则进行实时拦截。联邦学习框架可用于隐私计算场景,各数据方上传的并非原始数据,而是梯度更新,差分隐私噪声系数设定为1.0。
借由上述八个环节所进行的系统规划,能够达成面向从零到一的大模型建树。于实际落地之际,要依据预算、算力以及数据规模来实施动态性的配置调整,建议首先借助70亿参数模型来验证流程,随后再逐步拓展至千亿级别。
智算多多