

 智算多多
智算多多联系我们

官方邮箱:service@zsdodo.com

公司地址:北京市丰台区南四环西路188号总部基地三区国联股份数字经济总部
关注我们

公众号

视频号
◎2025 北京智算多多科技有限公司版权所有 京ICP备 2025150592号-1  京公网安备11010602202532号
京公网安备11010602202532号
京公网安备11010602202532号 超声影像凭借实时、无辐射的优势,成为临床各场景的一线诊断手段。
但异质的解剖结构、多样的诊断属性,让通用视觉语言预训练模型难以直接适配,且现有医疗跨模态数据中超声样本占比不足5%,成为领域研究的核心瓶颈。
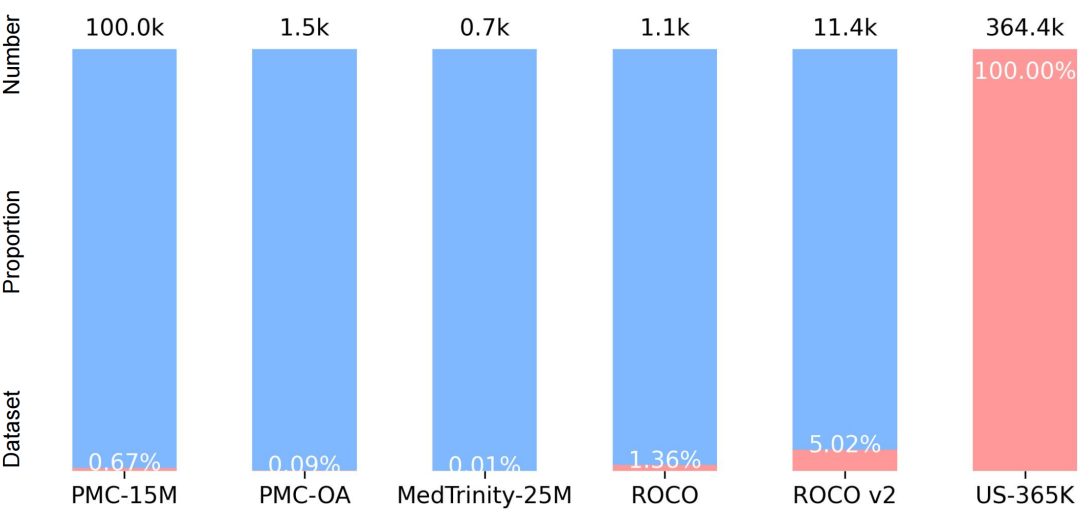
上图红色区域和内部百分比显示了超声图像所占的比例,而蓝色区域则展示了其余模态的占比情况。顶部标签表示绝对数量(以千为单位)。论文中所提出的US-365K是首个大规模、100%专用于超声影像的数据集。
针对这一问题,浙大城市学院联合浙江大学、香港城市大学、香港浸会大学、浙江大学医学院附属第一医院、浙江大学医学院附属妇产科医院等团队,构建了首个大规模通用超声图像-文本数据集US-365K,并提出专为超声场景设计的语义感知对比学习框架Ultrasound-CLIP,让模型真正理解超声的临床诊断语义,相关成果被CVPR 2026接收,数据集及代码已开源。
现有视觉语言模型在超声领域的应用,始终面临三个关键问题:
上图中(a) UDT作为语义基础,通过标准化解剖层次结构(UHAT)和定义9个关键诊断属性(UDAF)来形式化超声知识。(b) Ultrasound-CLIP利用UDT的方式有两种:(1)基于UDAF的异构图编码器通过交叉注意力将属性关系融合到文本嵌入中,以建模结构化推理。(2)构建基于UDAF的语义先验,以实现双目标优化,从而解决歧义。该框架将视觉特征与这些图增强的、语义感知的文本表示对齐。
为从根本上解决上述问题,研究团队立足超声临床诊断的专业逻辑,从标准化数据构建和定制化模型设计两大维度出发,打造全链路适配超声场景的跨模态学习体系,实现双重核心技术突破。
团队率先建立超声诊断分类体系(UDT),为超声数据的标准化标注和模型学习确立统一的专业依据,该体系包含两大核心模块,实现超声诊断知识的结构化、形式化:
基于UDT标准化框架,团队从5个国际权威医疗数据库收集体量超声数据,经多步骤精细化处理:先过滤非超声内容,将超声视频按0.5秒间隔分解为静态帧,平衡数据多样性与冗余性;再基于UDAF框架,通过大模型+结构化提示的混合流水线,提取标准化诊断标签;最后经医疗专家逐例审核、筛选,剔除模糊、不一致样本,最终构建出US-365K数据集。
该数据集包含36.4万对超声图像-文本样本、11676个临床真实病例,覆盖全解剖区域,是业内首个100%专属超声的大规模图文数据集,数据有效率超90%,填补了超声跨模态大规模标准化数据的行业空白,为超声AI研究奠定高质量数据基础。
针对超声场景的语义模糊和结构缺失难题,团队设计出Ultrasound-CLIP语义感知对比学习框架,在经典双编码器(图像+文本)基础上,创新融入UDAF引导的异质图编码器和基于UDAF的语义软标签两大核心模块,并采用双目标优化策略,让模型具备超声领域的结构化临床推理能力,突破通用模型的局限:
团队将每个超声样本的文本标注,转化为样本专属的异质图:基于UDAF框架定义诊断节点和属性节点两类核心节点,根据样本的标准化诊断标签确定激活节点集,并在诊断节点与属性节点间构建全二分连接,形成病灶-属性的关联图结构。
通过轻量级异质图神经网络(GNN)对异质图进行编码,得到包含节点关联信息的节点嵌入,再经注意力池化生成图汇总向量,最后通过多头交叉注意力将图嵌入与原始文本嵌入融合,并通过门控残差连接实现稳定融合,得到图增强的文本嵌入。这一过程让文本嵌入融入超声诊断标签与属性的结构化临床关联,突破单纯关键词匹配的局限,让模型能捕捉超声诊断的专业语义逻辑。
框架采用对比损失+语义损失的双目标优化策略,让模型同时实现图像-文本跨模态精准对齐和语义特征的正则化:
通过双目标联合优化,模型既能实现超声图像与文本的精准跨模态对齐,又能精准捕捉超声诊断的细粒度语义特征,真正理解超声的临床语言。
团队以US-365K为基础,在多任务分类、图像-文本检索任务中开展实验,并在4个公开的超声下游数据集上验证模型泛化能力,结果显示Ultrasound-CLIP全面优于现有医疗CLIP基线模型:
为推动超声跨模态学习领域的发展,团队已将研究相关的代码和US-365K数据集公开,为后续研究者提供可直接复用的基础资源。
 智算多多
智算多多官方邮箱:service@zsdodo.com
公司地址:北京市丰台区南四环西路188号总部基地三区国联股份数字经济总部
京公网安备11010602202532号