







 智算多多
智算多多联系我们


关注我们

公众号

视频号
隐私协议用户协议
◎ 2025 北京智算多多科技有限公司版权所有京ICP备 2025150592号-1
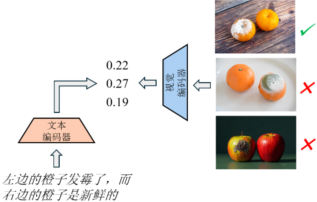
本文聚焦于多模态大模型(MLLM)在组合推理任务中的关键缺陷。组合推理要求模型准确理解图像与文本中物体、属性及其空间、逻辑关系的结构性绑定,是实现高级视觉理解的基础。然而,现有主流视觉语言模型(VLMs)如CLIP的训练机制并未显式建模这种结构化的互补性,而是过度依赖整体语义匹配,导致文本的结构信息被忽视,无法有效约束视觉表征的学习。如图1所示的例子,给定文本“左边的橙子发霉了,而右边的橙子是新鲜的”,CLIP模型对一张物体位置颠倒的负样本图像给出了更高的相似度得分(0.27 vs. 正确样本的0.22),而位置信息一致但实体错误的负样本则给出了更低的相似度得分(0.19 vs. 正确样本的0.22),表现出明显的实体识别能力与空间推理盲区。
这一缺陷被继承至使用CLIP作为视觉编码器的MLLM中,导致模型即使在GPT-4o等前沿系统中仍出现视觉感知与语言推理脱节的现象,如图2所示。
本研究选用组相对策略优化算法(GRPO)作为核心优化方法。GRPO 在保持训练稳定的同时,显著提升了实现效率与训练便捷性,特别适用于大规模模型的微调场景。GRPO 无需引入额外的价值网络来估计状态价值,而是通过组内回复之间的相对奖励比较来构建优势信号,从而避免了价值模型带来的计算开销和拟合噪声。具体而言,对于给定的问题 q,从当前策略中采样 G 个候选回复,并利用基于规则的奖励函数为每个回复计算得分。随后,将每个回复的优势定义为归一化后的奖励偏差:
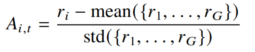
原始数据中存在大量噪声样本,其正负例差异多集中于物体是否存在,而非属性、位置或逻辑关系的细微变化,易导致模型依赖粗粒度识别而非精细推理。为此,本文从TripletData中采样18.5万个图文对,结合文本与视觉双模态信息进行联合过滤。
在文本层面,使用SBERT计算正例与难负例描述之间的语义相似度,设定阈值为0.7。保留语义高度相似但关键关系不同的样本,确保模型必须理解句中属性与主体的精确绑定,而非依赖关键词匹配。在视觉层面,采用DINOv2提取图像特征并计算正负图像的表示相似度,阈值设为0.75。该步骤保留仅在颜色、位置或姿态等局部细节上存在差异的图像对,排除整体内容差异过大的低质样本,促使模型关注细粒度空间结构。
上述双重过滤机制淘汰了约90%的初始样本,最终构建出一个高质量数据集,共包含18900个样本。
为系统提升多模态大语言模型的组合推理能力,本文基于构建的高质量数据集,设计了三种可自动验证、规则明确的互补任务,统称为组合推理指令任务。这些任务通过提示词模板将原始图文对转化为结构化指令,适配于基于规则奖励的强化学习框架。
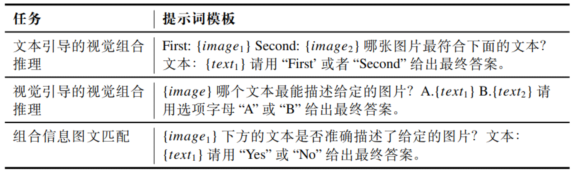
三种任务的具体模板如表1所示。此外,为提升训练稳定性,候选选项顺序在TG-VCR和VG-TCR中随机打乱,以消除位置偏差;CITM则确保类别均衡。最终,三类任务共同构成一个高质量、多任务、可验证的指令数据集,为强化学习提供可靠监督信号,全面增强模型的组合推理能力。
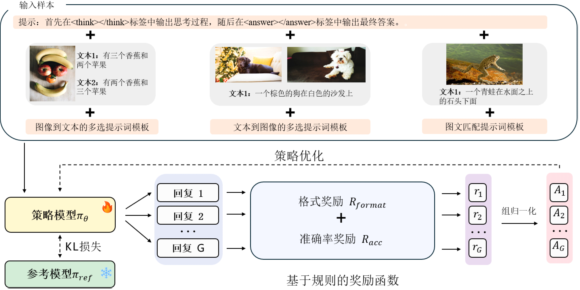
最终的训练方案如图3所示,GRPO算法在三种组合推理训练任务对应的指令数据上,重复采样生成多个回复,利用基于规则的奖励函数计算每个回复的奖励分数,通过组归一化的策略得到每个回复的相对优势A,进而优化模型参数增加模型生成更优回复的概率。
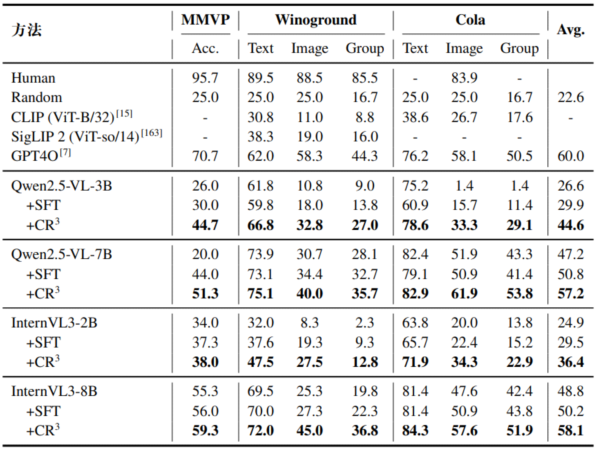
为评估CR³的增强效果,本文在MMVP、Winoground和Cola三个具有挑战性的组合推理基准上进行了零样本测试,涵盖Qwen2.5-VL与InternVL3等主流多模态大模型。如表2所示,CR³在所有模型上均实现显著且一致的性能提升。例如,Qwen2.5-VL-7B的平均得分从47.2提升至57.2(+10.0),InternVL3-8B从48.8提升至58.1(+9.3),平均提升超过9个绝对点,显著缩小了与GPT-4o(60.0)的差距。在关键的组合理解指标(如组得分)上提升尤为明显,如InternVL3-8B在Cola上的组得分提升达9.5点,表明模型在跨模态联合推理能力上取得实质性突破。相比监督微调(SFT),CR³平均仍领先5个点以上,验证了基于规则的强化学习能更有效引导模型探索正确推理路径。
如表3所示,CR³在多种通用多模态任务上也实现稳定且显著的性能提升,展现出强大的泛化能力。以Qwen2.5-VL-7B为例,CR³在MMMU上提升5.3分(46.7→52.0),MMBench提升2.2分,MMStar提升3.0分;在InternVL3-8B上,各项指标也全面领先,MMBench达86.4,接近性能上限。同时,CR³在HallusionBench上的幻觉率持续下降(如47.3→49.5),表明其推理更一致、可信。相比之下,监督微调(SFT)提升有限,甚至导致多个任务性能下降,如Qwen2.5-VL-3B在VSR上下降5.1分,InternVL3-2B在MMMU上下降2.0分,显示出SFT易过拟合、损害泛化能力的局限。
本文提出了基于规则的强化学习组合推理增强框架CR³,首次将强化学习用于系统性增强多模态大模型的组合推理能力。通过高质量的数据筛选与模型自适应的动态任务混合策略,CR³有效引导模型学会对物体、属性与关系进行精确绑定和深层理解。大量实验表明,CR³在多个主流多模态基准上平均提升超过9个绝对点(部分任务提升超19%),显著优于监督微调等传统方法。此外,CR³还系统性增强了其在空间理解、计数、OCR、幻觉抑制等细粒度任务上的能力,推动模型提升真实复杂场景的感知能力。
智算多多