







 智算多多
智算多多联系我们


关注我们

公众号

视频号
隐私协议用户协议
◎ 2025 北京智算多多科技有限公司版权所有京ICP备 2025150592号-1
在本文中,我将分析OpenAI的GPT-4o与Anthropic的Claude 3 Opus和Google的Gemini 1.5的多语言性能。
展示每个LLM在西班牙语、德语、法语、葡萄牙语和俄语等各种语言中的表现,以及更多小众语言。
GPT-4o(“o”代表“omni”)是OpenAI发布的最新模型。其名称反映了它处理各种内容形式(文本、音频和视频)的能力。
它首先在速度上表现出色,并且旨在通过其快速的标记预测使AI民主化大众化。
除了速度外,GPT-4o在复杂任务和推理能力方面也表现出色。
此外,OpenAI将发布一个桌面应用程序,用户可以通过音频与模型实时交互。
GPT-4o目前的定价为$5.00 / 1M tokens,这相当于:
$1.25 / 1百万(字符)
Google 的 Gemini 1.5 是 Gemini 系列的最新产品,从头开始构建为一种多模态模型,能够处理文字、图片、视频、音频和代码。
它可以无缝集成到 Google 的生态系统中,比如 Gmail 和 G Suite 的其他部分,我们很快就会在每个 Google 产品中看到 AI 功能。
众所周知,Google 以提供可扩展和可靠的服务而闻名,这在围绕 LLMs 构建产品时非常重要。
Gemini 已经将其价格降低到每 128k 上下文为 $3.5 / 1 百万 tokens,当转换为字符时,变为:
$1.25 / 1 百万(字符)
Anthropic's Claude 3 Opus专注于安全性和对齐性,同时提供竞争力强的语言性能。
具有低幻觉率,Claude 3 Opus擅长处理英语和欧洲语言,并在亚洲和小众语言方面不断改进。
它在准确处理非常长的文档方面表现出色 - 这使得它非常适合RAG应用,如果您想要最佳性能。
然而,作为其高性能的副产品,它被认为是昂贵且有些慢。
Claude 3 Opus目前定价为$15 / 1 million tokens,大约相当于:
$4.3 / 1 百万(字符)
在封闭源LLM API之上可扩展的应用程序可能很昂贵。抛开价格谈性能,都是。。
在分析模型性能时,请牢记这些价格!

评估框架中使用了先前文章中描述的数据集
该数据集包括每种语言下分类为50个不同主题的200个句子(其中一些密切相关)。
手动创建了英语数据集,并使用GPT-4将数据集翻译成多种语言。
语言模型的任务是将每个句子与正确的主题匹配,从而实现每种语言的准确度测量。
首先,我想比较OpenAI最突出的模型 - 因为我已经读到了关于GPT-4o性能的许多抱怨。
考虑到GPT-4o的价格是GPT-4 Turbo的一半,比GPT-4便宜六倍,这个比较应该能提供有价值的见解。
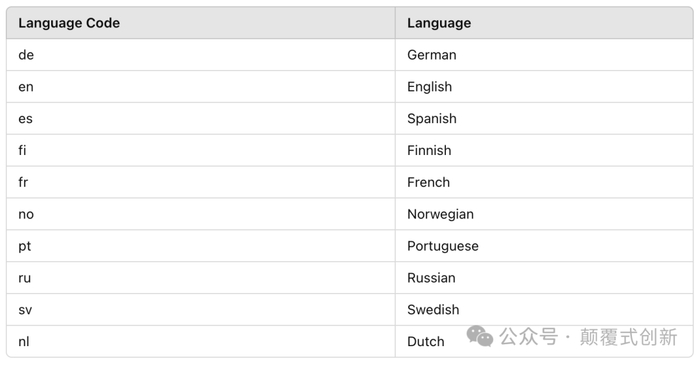
选择最突出的欧洲语言和一些更小众的语言。如果你对语言代码不熟悉,可以参考下面的表格:
第一步是在所有OpenAI的模型上运行评估框架,收集每种语言代码的准确性分数。
然后我创建了一个雷达图来可视化每种语言代码的每个LLM的性能。我个人认为雷达图是呈现这些性能差异最美观的方式。

简单回顾一下雷达图的工作原理,性能更好的模型会延伸到边缘。而性能较差的模型会保持在靠近中心的较小圆圈内。
从图中我们可以得出,根据这个测试,GPT-4o通常比GPT-4和GPT-4 Turbo更出色 - 表明整体性能更好。
葡萄牙语是唯一一种GPT-4o在这个测试中表现不佳的语言 - 然而,由于数据集很小,这种表现不佳在统计上并不显著,可能是由于随机变化或数据集中特定挑战所致。
有趣的是,我们看到GPT-4o在俄语和芬兰语中有明显的性能提升。
注意:机器学习工程师职业生涯中,优化芬兰语NLP任务存在问题,因为它是一种相对小众的语言 - 但看起来GPT-4o最终打破了这一模式!
在对OpenAI的顶级LLMs进行比较后,我选择了Claude 3 Opus和Gemini 1.5来看它们与GPT-4o相比如何。
这些模型真正展示了在各种任务中的最先进的语言理解能力,并且都展示了强大的多语言能力。
我采用了之前比较中使用的相同评估框架。
该框架测试了每个模型在各种语言代码上的表现,使我们能够为每种语言生成详细的性能概况。
让我们看看GPT-4o在竞争对手中的表现如何。
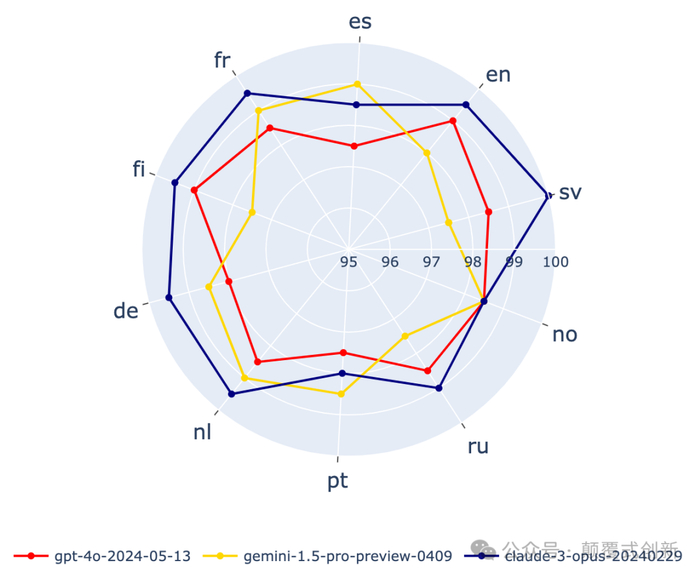
正如图表所示,所有模型的表现都相当不错。值得注意的是,图表是按比例缩放的,从95%的准确率开始,到100%。
这意味着所有三个LLMs在所有语言中的得分都在97.5%到100%之间,展示了出色的多语言能力。
然而,图表显示了一个趋势,即Anthropic的Claude 3 Opus在大多数语言中略领先 - 这似乎是一致的。与Gemini相比,Claude 3 Opus只在两种语言中表现不佳,并且从未被GPT-4o超越。
Anthropic的Claude 3 Opus是目前最强大的LLM吗?
使用Claude 3 Opus而不是GPT-4o或Gemini 1.5值得支付六倍的费用吗?
在对 OpenAI 的 GPT-4o、Anthropic 的 Claude 3 Opus 和 Google 的 Gemini 1.5 进行多语言评估时,出现了一些关键的见解。
在这些模型之间的选择应考虑成本、特定的语言要求和更广泛的生态系统集成需求。
随着语言模型的发展不断演变,看到这些模型如何进一步发展,以及是否会出现全新的模型来挑战它们当前的能力和市场主导地位,将会非常有趣。
智算多多