







 智算多多
智算多多联系我们


关注我们

公众号

视频号
隐私协议用户协议
◎ 2025 北京智算多多科技有限公司版权所有京ICP备 2025150592号-1

论文:http://arxiv.org/pdf/2512.23035
代码:https://xavierjiezou.github.io/Co2S/
这篇文章属于遥感图像语义分割与半监督学习的交叉方向,更具体地说,是基于视觉基础模型(Vision Foundation Models)的半监督遥感分割。论文关注的现实痛点很明确:遥感图像像素级标注代价高昂,而已有半监督方法又容易在训练中不断强化错误伪标签,导致性能不稳定。为此,作者引入CLIP 这类视觉-语言模型与 DINOv3 这类自监督视觉模型的异质先验,希望通过两类基础模型的互补能力,提升低标注场景下的训练稳定性。
从问题设定上看,论文并不是单纯追求更高的 mIoU,而是把“如何稳定地利用未标注数据”作为主线。作者明确指出,传统 consistency learning、pseudo-labeling、GAN-based 方法在遥感复杂场景中容易受到语义混淆、边界模糊和噪声累积的影响,因此需要更强的外部先验来纠偏。
论文提出的方法名为 Co2S。整体上,它是一个异构双学生(dual-student)半监督分割框架:上分支采用 CLIP-based student,下分支采用 DINOv3-based student。二者都基于 ViT,但预训练来源不同,因此具备不同的表征偏好。作者的设计思想是:
论文认为,这种“异质性”比传统同构双网络更重要,因为同构模型虽然初始化不同,但往往会收敛到相似错误模式;而异构双学生更可能互相纠错,从源头减轻伪标签漂移。这个整体框架示意见图2。
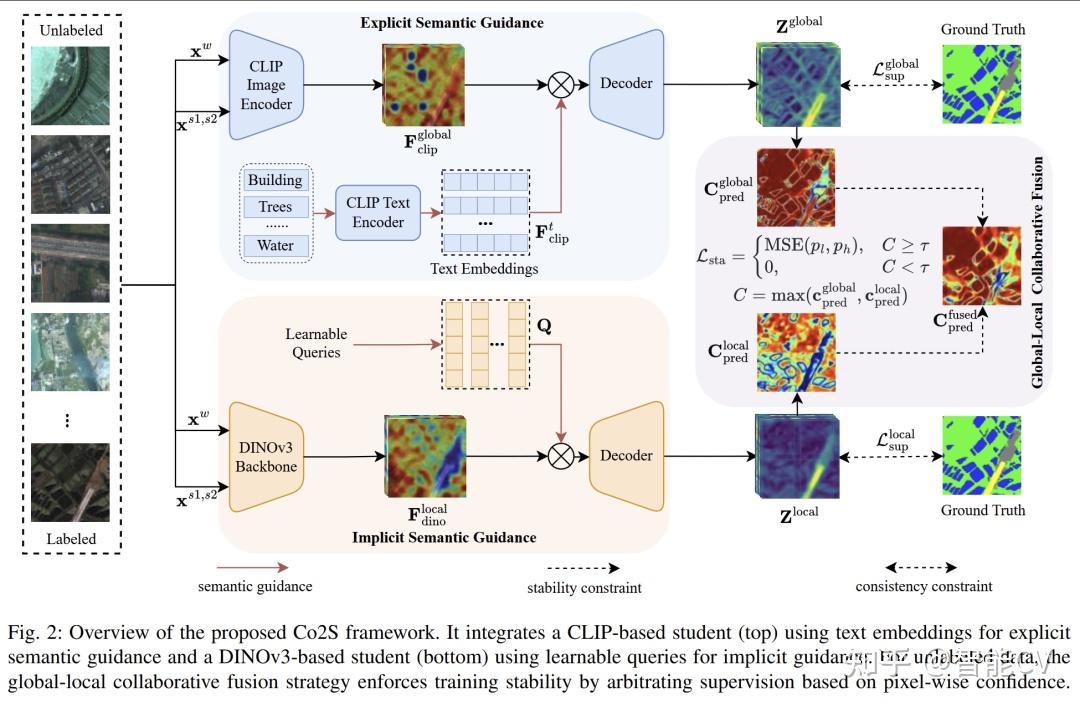
这是论文最核心的创新之一。作者提出了 Explicit-Implicit Semantic Collaborative Guidance:
对于 CLIP 分支,作者利用冻结的 CLIP 文本编码器,将每个语义类别构造成若干细粒度概念描述,再通过 prompt 编码得到类别原型,形成显式文本查询矩阵。这样做的本质是:把语言层面的类别先验直接引入分割解码过程,使模型在极少标注时也能获得稳定的类别语义锚点。相关公式见文中公式 (5)(6),整体流程可对应图2上半部分。
对于 DINOv3 分支,作者不使用文本,而是引入一组可学习查询向量,作为隐式类别级表示。这些 query 会和 DINOv3 backbone 一起训练,逐步适应遥感影像的视觉分布。相关定义见公式 (7),同样体现在图2下半部分。
论文强调,这两类语义并非各自独立。虽然前向传播时文本嵌入和 learnable queries 分开工作,但在优化阶段会通过稳定性损失耦合起来:
所以它不是简单“两个模型做平均”,而是一种显式语义纠错 + 隐式视觉细化的协同学习机制。
第二个关键创新是 Global-Local Feature Collaborative Fusion。作者通过注意力可视化发现,图3 中 CLIP 的注意力通常更分散,更偏向全局上下文;而 DINOv3 的注意力更集中,能够更好捕捉局部细节和目标边缘。基于这一观察,论文提出按像素置信度进行协同监督:
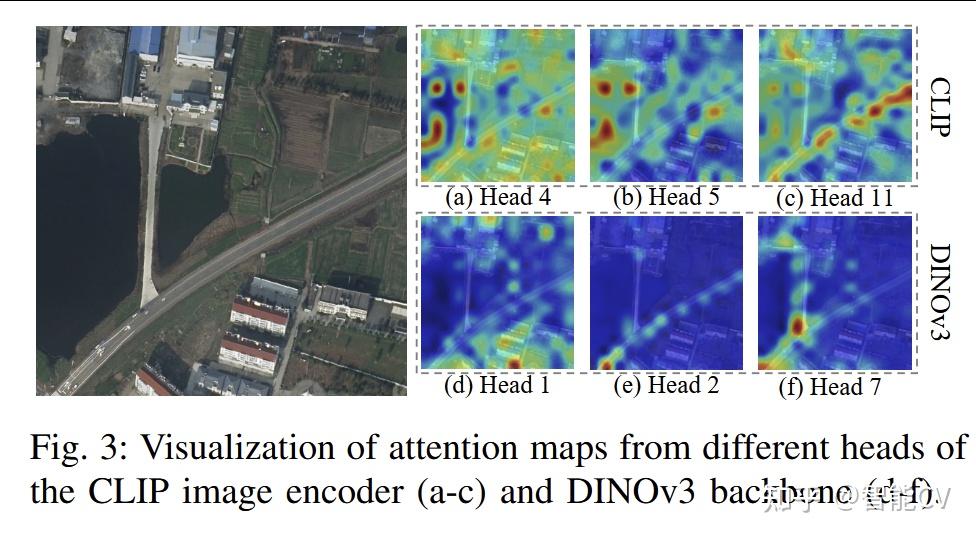
这一机制通过稳定性损失 L_{sta}实现,本质上是在优化层面做“仲裁式融合”,而不是粗暴平均。它的作用是把 CLIP 的全局语义与 DINOv3 的局部纹理结合起来,让预测结果同时具备类别正确性和边界精细性。对应说明见图2右侧灰色模块、图3以及公式 (9)(10)(11)(12)。
在训练流程上,Co2S 沿用了 UniMatch 式的弱增强—强增强—特征扰动范式,对未标注样本生成弱视图、两种强视图和 feature-perturbed 视图,并用高置信伪标签构造一致性损失 LctL_{ct}Lct。在此基础上,作者额外引入稳定性损失 LstaL_{sta}Lsta,令总目标函数为监督损失、一致性损失和稳定性损失三项加权和。也就是说,本文并不是推翻已有半监督训练范式,而是在其上加入异构基础模型先验和跨分支稳定约束,从而显著增强训练可靠性。公式见 (1)(2)(3)(4)。
作者在 6 个常用遥感分割数据集上验证方法,包括:
覆盖地球观测与火星地表场景,数据来源、空间分辨率、类别数和复杂度都较多样。评估指标采用 mIoU。这些数据集和设置在实验部分有明确说明。
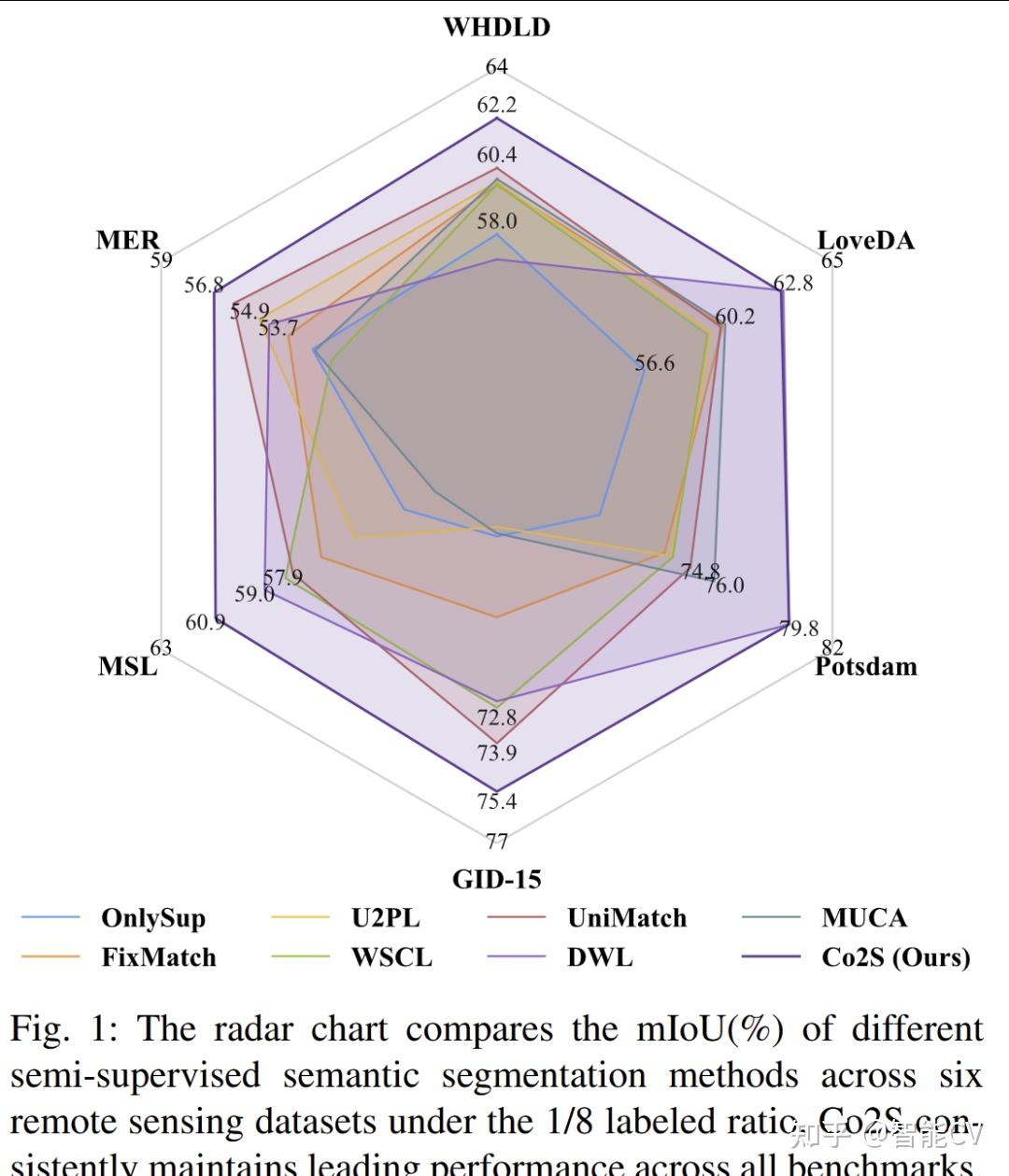
·从图1的雷达图可以直接看出,在 1/8 标注比例下,Co2S 在 6 个数据集上都保持了领先或并列领先的总体表现,是整篇论文最直观的总览图。图中对比了 OnlySup、FixMatch、U2PL、WSCL、UniMatch、DWL、MUCA 等方法,Co2S 在六个基准上呈现出最均衡、最稳定的结果。
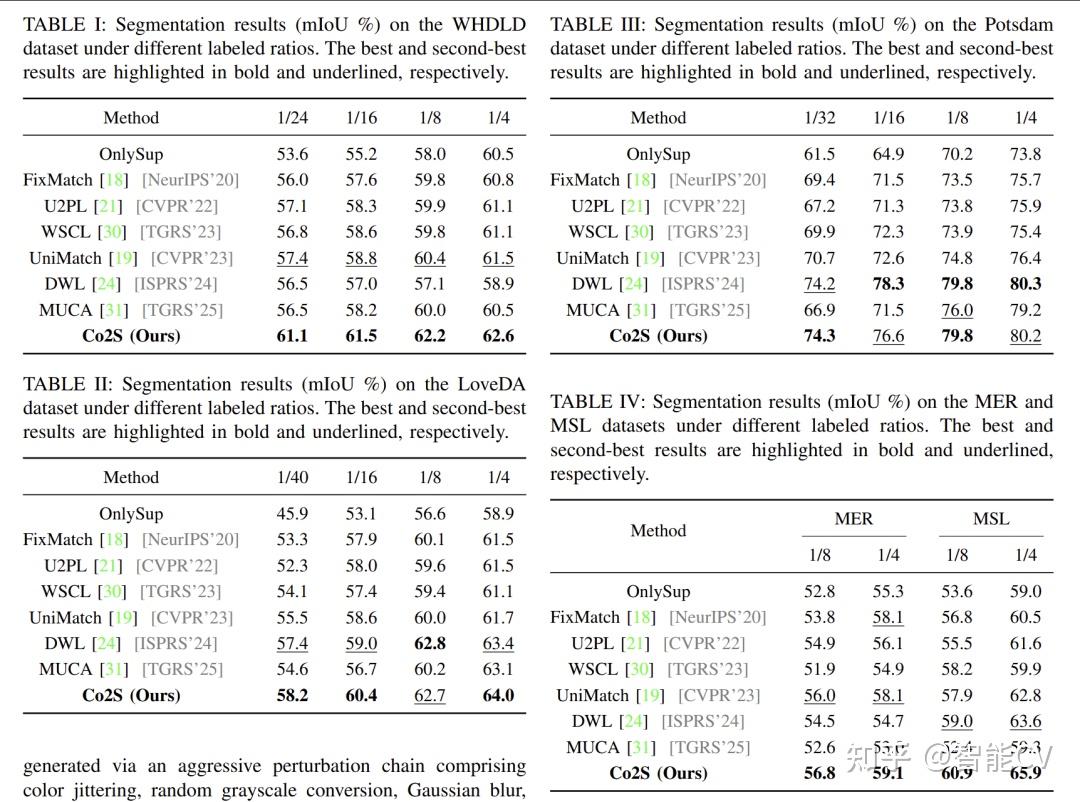
见表1。在 WHDLD 上,Co2S 在不同标注比例下分别达到:
其中在最苛刻的 1/24 设置下,Co2S 相比 UniMatch 的 57.4 提升 3.7 个点;相比 OnlySup 的 53.6 提升更大,说明方法在极少标注下尤其有效。
见表2。Co2S 在 LoveDA 上取得:
尤其在最少标注的 1/40 下,较 OnlySup 的 45.9 高出 12.3 个点,说明其在存在显著城乡域差异时,依然能依靠 foundation model 先验维持较强的泛化。
见表3。Co2S 在 1/32、1/16、1/8、1/4 下分别达到 74.3、76.6、79.8、80.2。
这说明 Co2S 在超高分辨率遥感影像上也具备很强竞争力。
见表4。
两个数据集上 Co2S 都取得最好结果,说明方法并不局限于地球遥感场景,对类别不平衡、纹理复杂的行星表面分割也有较好适应性。
见表5。GID-15 上:
对比 UniMatch,在 1/8 设置下从 73.9 提升到 75.4,提升 1.5 个点。说明在类别更多、地物细粒度差异更复杂时,Co2S 依然具备稳定优势。

图4 给出了六个数据集在 1/8 标注比例下的可视化对比。作者指出,许多基线方法在复杂场景中容易出现类别混淆:
而 Co2S 在这些例子中总体表现出更准确的类别判别和更规整的边界,证明其确实实现了“全局语义稳定 + 局部细节精确”的目标。
图5 是这篇论文很有说服力的一张图。作者在 WHDLD 的 1/24 设置上,统计了前 10 个 epoch 中伪标签准确率的变化。结果显示:
这直接支持了作者的核心主张:Co2S 能有效抑制伪标签漂移,而不是只在最终 mIoU 上略有提升。
见表6。
结果表明,显式文本语义贡献更大,而隐式 query 单独使用效果有限;但当二者协同时效果最好,说明二者确实互补。
见表7。
这说明论文的关键不只是“双学生”,而是异质先验协同。同构 DINOv3 会严重语义漂移;同构 CLIP 虽然较强,但互补性不足。
见表8。
说明 LstaL_{sta}Lsta 不是装饰项,而是提升性能与训练稳定性的关键部分。
见表9。作者比较了 CLIP 与 MAE、BEiTv2、iBOT、SimMIM、DINOv3 的组合,最终 CLIP + DINOv3 最优,达到 61.09,说明 DINOv3 与 CLIP 的互补性最好。
这篇文章的价值主要体现在两个层面。
第一,它并没有只停留在“换一个更强 backbone”这种套路上,而是围绕半监督训练不稳定、伪标签漂移严重这一核心痛点,提出了比较完整的解决思路:
第二,实验非常充分。论文不仅在 6 个数据集上展示了稳定领先的 mIoU,还通过图4 的可视化和图5 的伪标签演化曲线说明:Co2S 的改进不是偶然的数值优势,而是训练机制层面的稳定提升。尤其在极低标注比例下,优势更明显,这也符合半监督任务最看重的实际需求。
整体来看,这是一篇面向遥感半监督语义分割、强调训练稳定性与基础模型协同利用的工作。创新点清晰,实验扎实,方法设计也有较好的可迁移性,对后续将 VLM/SSM 引入遥感低标注学习具有较强参考价值。
智算多多