







 智算多多
智算多多联系我们


关注我们

公众号

视频号
隐私协议用户协议
◎ 2025 北京智算多多科技有限公司版权所有京ICP备 2025150592号-1
本数据集基于中国A股上市公司财务数据构建,涵盖2010—2024年间全部A股上市公司(已剔除金融业、ST、ST*、PT类公司以及数据缺失或异常样本),并进行缩尾处理,最终获得数万条公司—年度观测值。数据来源于CSMAR数据库,并在原始财务指标基础上,依据行为企业理论构建了绩效期望盈余(PAS)指标。
数据集包含以下字段:企业代码、企业简称、年份、资产回报率(ROA)、行业代码;衍生指标包括:历史期望水平(企业前两年ROA的算术平均值)、行业总ROA(同行业同年份所有公司ROA之和)、行业公司数(同行业同年份公司总数)、行业平均ROA(剔除企业自身后的同行业同年份平均ROA)、期望绩效(A,由历史和行业期望水平加权合成)、期望值差(实际ROA与期望绩效之差)、二元虚拟变量(I,实际绩效是否超过期望绩效,超过取1否则取0),以及最终核心指标——绩效期望盈余(PAS = I × 期望值差)。该指标既捕捉了企业是否处于高绩效状态,又度量了超出期望的具体幅度,能够有效刻画企业的高绩效程度。
基于本数据集可展开以下三方面研究:
PAS的测度借鉴Chen(2008)的研究框架,兼顾历史与行业双重基准。具体步骤如下:
所有基础财务指标均来源于CSMAR数据库,经清洗、匹配与缩尾后形成本数据集。
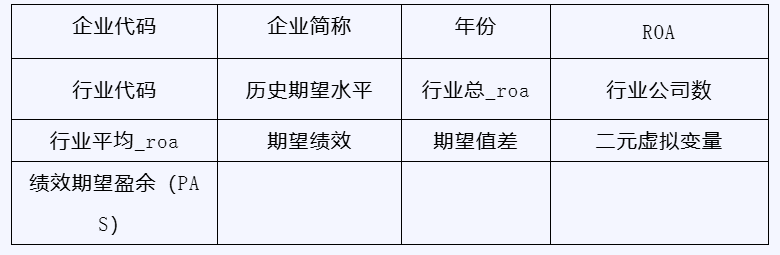
数据字段截图
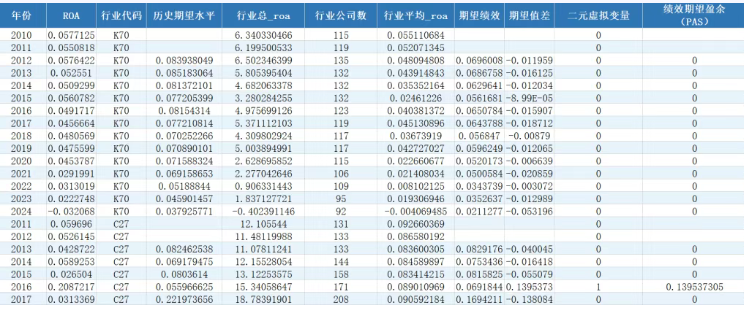
数据截图
智算多多