







 智算多多
智算多多联系我们


关注我们

公众号

视频号
隐私协议用户协议
◎ 2025 北京智算多多科技有限公司版权所有京ICP备 2025150592号-1
面向软件工程的 Code Agent 快速走向实用,它们已经可以在真实仓库里完成根据 issue 去浏览代码并修改,在运行测试通过后提交 PR 的步骤,并在 SWE-bench 等真实修复基准上不断提升。
无论是人还是 agent 首先都绕不开应该改哪里的问题,在工业实践里,开发者排查 bug 往往把大量时间花在定位相关文件或函数、沿依赖关系追踪调用链、以及回溯历史变更上。
对 agent 而言定位失败会直接导致检索到的上下文无关、修改位置偏离,甚至在错误模块乱修。
近期针对软件工程智能体的分析也指出,很多失败案例并不是不会写补丁,而是首先没能准确锁定 buggy 文件。
很多修复任务真正拉开差距的地方,就在于能不能在庞杂仓库里尽快找到那个真正该改的位置。
GNN 的优势正好与此互补,图上的消息传递天然适合建模结构依赖及多跳传播,但长期制约这个方向发展的难点在于一直没有真正面向仓库级 Bug 定位的图 benchmark 和图数据。
现有基准大多服务于文本检索、文件级定位或端到端修复,缺少能直接用于 GNN 训练与评测的仓库图表示。
北京大学张牧涵团队推出 GREPO 的贡献就是把这块最难、最基础的地基完整铺好了,不仅能直接支持 GNN 训练也能兼容所有 code agent。

图1. GREPO 的规模与效果概览(左:任务规模对比;右:9 个代表性仓库上 GNN 与强基线对比)。
它首次提供可直接使用的异构时序仓库图,覆盖 86 个真实 Python 仓库和 47,294 条真实修复任务,把历史快照锚定、增量构图、严格泄漏控制和统一评测协议整合成一套完整标准,而且可以支持研究者根据自己需要对于任意 GitHub 仓库都能生成数据。
GREPO 把仓库级 Bug 定位推进到可规模化研究的标准图学习任务,统一数据结构、统一输入约束、统一指标,并配套榜单。

论文标题:
GREPO: A Benchmark for Graph Neural Networks on Repository-Level Bug Localization
论文链接:
https://arxiv.org/abs/2602.13921
代码链接:
https://github.com/qingpingmo/GREPO
数据集链接:
https://modelscope.cn/datasets/qingpingmomo/Grepo
排行榜链接:
https://pku-mulab-grepo.netlify.app/
指标:Mean Query Recall(Hit@K)
对每个 issue ,记真实需要修改的节点集合为 ,模型输出的 Top-K 为 Topk(q),则:

最终得分为测试集上所有 issue 的平均值。论文在 上报告结果。
GREPO 在每个仓库内按 issue 创建时间做时间序切分:80% 作为训练、20% 作为测试。所有模型在 86 个仓库的训练集合并训练。
评测时论文重点报告 9 个代表性仓库(astropy、dvc、ipython、pylint、scipy、sphinx、streamlink、xarray、geopandas)的测试集表现,并额外提供 0-shot 设置(这 9 个仓库完全不参与训练)以检验跨仓库泛化。

图2. 基准对比与任务统计(Table 1/2)。GREPO 在仓库数量与任务规模上显著扩大,并给出了修复任务复杂度的分位数统计。
GREPO 是一套能够承载跨文件依赖推理的图结构。它把仓库在某个 commit 的结构与语义依赖编码成异构图,并用时间信息把同一实体在不同版本串联起来。
首先使用 Tree-sitter 从 AST 中抽取定义节点与包含关系;随后使用 Jedi 在源码位置级别解析调用与继承,并通过(相对路径, 定义起始行号)的 join key 将 Jedi 的解析结果映射回图中的定义节点。
这种分工利用了两类工具的互补性:Tree-sitter 稳定识别语法结构,Jedi 更擅长解析符号引用。

图3. 数据集构建总览。来源:原论文 Figure 2。

图4. 单 commit 构图流程。来源:原论文 Figure 3。

图5. 增量式构图收益。来源:原论文 Figure 4。
如果对每个 commit 都从零重建整张仓库图,成本会随 commit 数量巨量增多。
GREPO 的做法是新 commit 到来时,只重解析 git diff 涉及的文件,未变化的节点与边直接复用,从而显著降低整体构建开销,如图 5 所示。
真实仓库历史是带分支与合并的 DAG。为了进行增量构图与在某个时间点切片取快照,论文采用从 commit DAG 中提取一条最长路径作为规范化时间轴,并在任务中只使用 bug 发生时间之前的历史信息,避免未来泄漏。
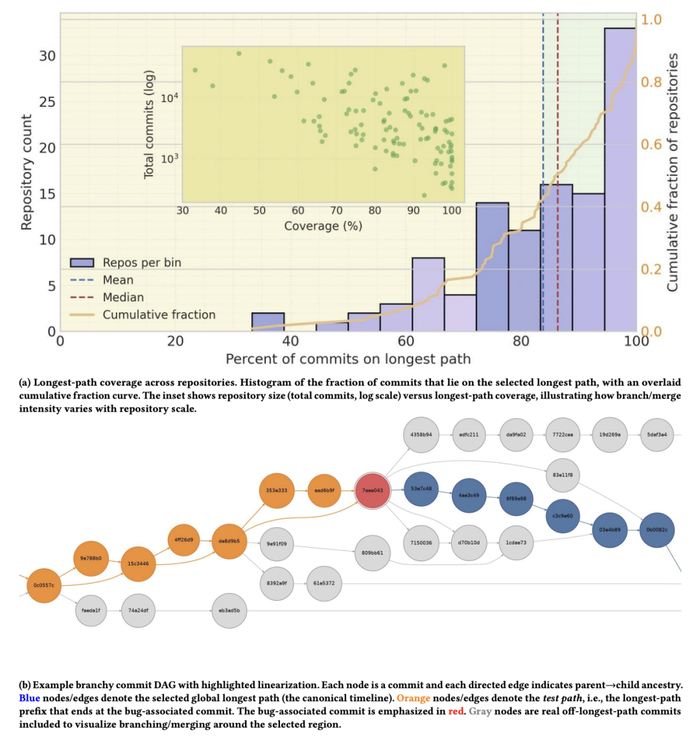
图6. 将分支合并的 commit DAG 线性化为最长路径时间轴(Figure 10)。来源:原论文 Figure 10。
Step 1:筛选有效修复 PR。通过 GitHub API 获取 PR 元数据和提交记录,只保留 merged PR,排除未被接受的修复。
Step 2:建立 issue 与 PR 的对应关系。
Step 3:控制信息泄漏,排除可能暴露修复细节的内容。
Step 4:规范化 issue body。
Step 5:生成函数或类级标签并映射到图,形成监督标签集合。
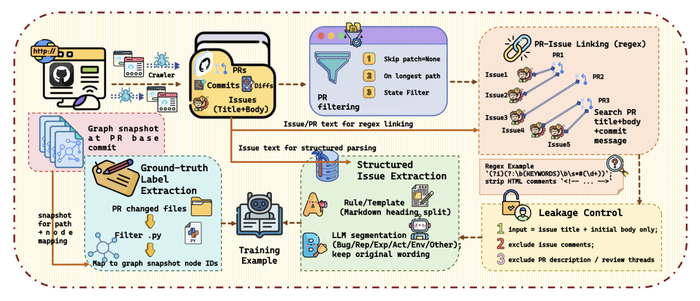
图7. 任务/标签构建pipeline。来源:原论文 Figure 5。
论文在统一的输入约束与切分下,对比了多类方法:LLM/Agent 系列与多种 GNN/Graph Transformer(统一训练设置)。
论文评测了 GCN、GraphSAGE、GIN、GAT、GATv2、GatedGCN 以及图 Transformer GPS 等多种架构,覆盖了经典消息传递与更强的注意力/全局建模变体。

图8. LLM/Agent 与 GNN 在 9 个代表性仓库上的主结果(Hit@K)
在 Average 列上,GATv2 的 Hit@1/5/10/20 均为最优或接近最优,显著超过 LLM/Agent 基线。
从 Hit@5/10/20 的差距看,GNN 的优势不仅体现在第一名是否命中,更体现在Top-K 覆盖真实修改集合的能力。
这符合仓库级定位的需求:真实修复往往涉及多个实体,需要高召回的候选集合。
GREPO 的规模允许做“像 NLP/视觉那样”的 scaling 实验:随着训练仓库数量从 10→20→40→77 增加,GAT 在 0-shot 设置下的各项 Hit@K 持续提升,提示存在可迁移的仓库级定位能力。

图9. scaling law(Figure 7)。来源:原论文Figure 7。
智算多多