

 智算多多
智算多多联系我们

官方邮箱:service@zsdodo.com

公司地址:北京市丰台区南四环西路188号总部基地三区国联股份数字经济总部
关注我们

公众号

视频号
◎2025 北京智算多多科技有限公司版权所有 京ICP备 2025150592号-1  京公网安备11010602202532号
京公网安备11010602202532号
京公网安备11010602202532号 The company introduced two variants:
The secret sauce? A clever innovation called Directory-Style Attention (DSA). Traditional AI models struggle with long documents because processing time grows exponentially with length. DSA changes this dramatically:
The result? These are the first open-source models capable of handling million-token documents on a single graphics card.
The DeepSeek team didn't cut corners on training either:
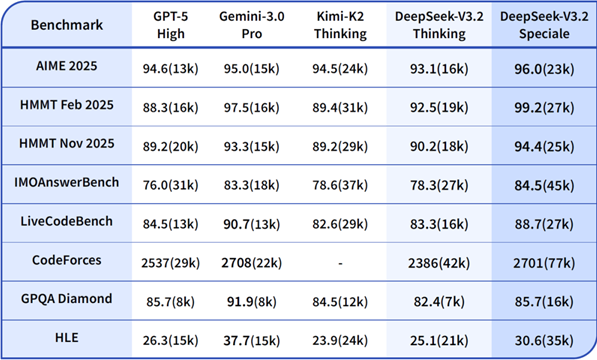
The payoff shows in testing - Speciale produces answers that are not only longer (32% more tokens than Gemini3Pro) but also more accurate (4.8 percentage points higher).
Both models are available now on GitHub and Hugging Face under the business-friendly Apache 2.0 license. DeepSeek promises more openness ahead:
"We're planning to release our DSA kernel and RL training framework next," a company spokesperson said.
The move continues DeepSeek's strategy of turning proprietary advantages into community assets - an approach that could reshape the competitive landscape by 2026 if they maintain this pace.
 智算多多
智算多多官方邮箱:service@zsdodo.com
公司地址:北京市丰台区南四环西路188号总部基地三区国联股份数字经济总部
京公网安备11010602202532号