

 智算多多
智算多多联系我们

官方邮箱:service@zsdodo.com

公司地址:北京市丰台区南四环西路188号总部基地三区国联股份数字经济总部
关注我们

公众号

视频号
◎2025 北京智算多多科技有限公司版权所有 京ICP备 2025150592号-1  京公网安备11010602202532号
京公网安备11010602202532号
京公网安备11010602202532号 考试考了几千年,还从来没人考过这个。
SAT考你数学,GRE考你词汇,再往前看:科举考试考你的八股文……
古今考试形式不同,但底层逻辑却很一致:考你知道什么。
但有一类能力,从来没有考试碰过:你跟人吵架时怎么办。
最近,Google Research推出了一个叫Vantage的实验项目,就把这件事给干了。

Vantage项目由谷歌联合纽约大学开发,主要设想是利用GenAI模拟团队协作场景,以此来开发和测量被测试者的软技能。
它会把你扔进一个AI角色扮演的协作场景里,然后让你和一群AI角色组队完成任务。
其中会有一个agent跳出来,专门按剧本跟你唱反调,抛不合理要求,搞情绪化反应。
你在压力下做出的每一个回应,都会被另一个Agent基于评分量表进行分析,生成评分与反馈。
整个过程中,你所面对的是一个被AI精心操控的「职场修罗场」:它考的不是你背了多少东西,而是你在压力下怎么做人。
谷歌联合纽约大学做了188人验证,结果显示:
AI评分与人类专家的一致性,跟专家与专家之间的一致性,处于同一水平。
这意味着,至少在「评判」这件事上,AI已经开始接近人类专家。
看来,考试这件事,以后可能要被重新定义了。
为什么软技能一直考不了?
这个事企业HR太清楚了:招人最怕的不是技术不行,而是进了团队才发现这人完全不会协作。
世界经济论坛2025年《Future of Jobs 2025》报告给了一组数据:到2030年,全球39%的核心职场技能将发生变化。
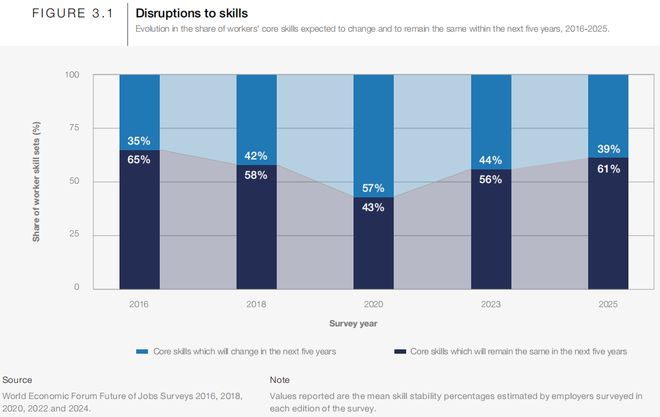
在企业最看重的能力排名中,分析思维排第一,紧随其后的是韧性、灵活性、领导力与社会影响力,排在最前面的几乎全是「软技能」。

AI时代,这些软技能仍然是最核心的技能。
问题是,怎么测?
传统标准化测试太僵硬了,题目难易捕捉人类思维过程和人际互动,跟真实场景隔着十万八千里。
基本上只能依靠两条。
靠谱是靠谱,但做一次往往价格不菲、耗时几天,评分还因为考官不同而漂移。
核心矛盾只有一条:软技能必须在互动中才能被观测,但标准化互动的成本太高,限制了它的实现和推广。
你不可能给每个学生配一个真人考官,让他们吵一架再打分。
所以几十年来,这一直是教育评估领域的一个老大难问题。
市场上也不是没人尝试。
HireVue用视频面试做AI情绪分析,Pymetrics用神经科学小游戏做性格测评,但它们都有一个共同局限:
候选人面对的,更多仍是被设计好的数字流程,而不是一个会跟你争论、会给你挖坑、会把互动不断推进下去的真实对手。
直到谷歌推出 Vantage,事情才开始变得不一样:它试图用多方AI角色协作生成情境,而且还把软技能测试的成本压到接近可规模化的水平。
Vantage不是一个AI在干活,而是一群AI在演戏,该系统的精巧之处在于架构设计。
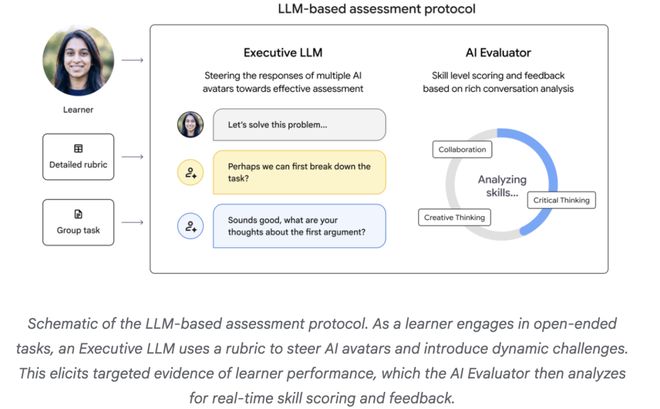
它不是一个AI出题、你来答题的传统路子,而是搭了一个四层架构,每层都有AI各司其职,同时运转。
这样四层解耦的好处很明显:场景可以换,角色可以换,评分标准可以换,但流水线本身不变,而且,模块化意味着可扩展。
今天测冲突解决,明天换个量表就能测项目管理,后天再换就能测谈判能力。
熟悉软件工程的人大概一眼就认出来了,这就是把微服务架构的思路,搬到了教育评估里。
架构再漂亮,不实测都是空谈。
谷歌和NYU做了一次联合验证。他们找了188名美国测试者,年龄18-25岁,在Vantage中完成了冲突解决和项目管理两个维度的评估。
然后,NYU的人类评分专家用同一份rubric对同样的对话记录打分。
结果很有意思。
人类专家之间的一致性,Kappa值为0.45到0.64,也就是中等一致性。

两个人类专家给同一段对话打分,经常打出不同的分数。
这不意外。
软技能评估本来就是主观判断密集的领域。
比如,一个人觉得候选人在冲突中表现出了「坚定但尊重」,另一个人可能觉得那叫「固执」。
而AI评分期跟人类专家之间的一致性呢?跟两个人类专家之间差不多,这意味着它的评分质量已经到了同一水平线上。
这听起来似乎没什么大不了,但在软技能评估这个领域里,这已经是一个了不起的基线。
更重要的是:人类专家一次只能评几个人,AI可以同时评几万人。
成本直接差了两个数量级。
很多人第一反应是:这不就是个花哨的AI面试官吗。
过去几年,AI面试工具层出不穷,大多数最后沦为噱头。
但Vantage更像是一个基础设施层,目前谷歌已公开 Vantage 的技术报告与实验介绍,外界已经能比较清楚地看到它如何用评分量表驱动情境生成、角色互动与结果评估。
从方法上看,这套框架具备一定的可迁移性:在理论上,研究者或机构可以围绕不同软技能设计相应任务与量表,并据此搭建类似的评估流程。
比如,企业可以探索把它用于领导力或协作场景的训练与评估,教育机构也可以把它用于协作能力练习和反馈。
这让人想起教育评估领域长期讨论的「形成性评估」:不是期末一次定结果,而是在学习过程中持续测量、持续反馈、持续调整。
过去这件事之所以难以规模化,一个重要原因是高质量互动评估往往依赖真人考官,成本高、耗时长、标准化困难。
而像Vantage这类基于生成式AI的模拟评估系统,则让这件事第一次呈现出更强的可扩展性。
当然,必须说清楚Vantage目前的边界。
Google Labs博客中将其定义为研究实验,它目前更接近一个公开可体验的研究实验,而不是已经大规模落地的成熟应用。

188人的验证规模不算大,只明确覆盖了协作中的冲突解决和项目管理两个维度,跨文化场景没碰,长期技能成长追踪没做,模拟环境里的表现能不能迁移到真实的人际互动,也还是个问号。
谷歌自己也承认,下一步要研究的正是这些。但这不妨碍Vantage这项实验的潜力。
OECD早就把创造力、批判性思维列进了教育系统的核心讨论。所有人都知道软技能重要,但没人真正解决过怎么测、怎么大规模地测。
Vantage给出了一个可能的答案。
Google Research博客里提到了这样一句话:
在全球教育体系中,被测量的东西往往就是被教授的东西。

这句话才是真正的炸弹。
如果软技能可以被量化评估,那学校教什么就会变。
现在学校考什么?知识、公式、标准答案。因为只有这些东西能标准化测量。
但如果有一天,协作力、冲突解决能力、创造力都能被精准打分了,课程设计的底层逻辑就会被改写。
企业招聘也一样。
今天的招聘流程看学历、看简历、看面试官的直觉。
如果AI可以在沉浸式模拟中直接观察一个人处理冲突的能力,并给出可量化的分数,面试这件事本身就会被重新定义。
个人成长也一样。
你的沟通能力、你的领导力,第一次有了可视化的进步曲线。
不再是「我觉得自己变强了」,而是「系统显示你的冲突解决得分从上个月的63提升到了71」。
这就是Vantage这个小实验背后的大故事:当「最难考的能力」变得可考,教育评估的边界就会被重新划定。
当AI能制造冲突、观察行为、提取证据、逐条打分,「考试」这个词的含义就永远变了。
它不再是你对着一张试卷独自奋斗,可能是你走进一个房间,面对一群不好对付的人,然后做你自己。
下一个被AI考的软技能会是什么?
也许是谈判,也许是共情,也许是你最不想被打分的那个东西。
当AI不仅能替代你的硬技能,还能给你的软技能精准打分的时候,你还觉得「情商」「协作力」是不需要认真对待的东西吗?
 智算多多
智算多多官方邮箱:service@zsdodo.com
公司地址:北京市丰台区南四环西路188号总部基地三区国联股份数字经济总部
京公网安备11010602202532号