

 智算多多
智算多多联系我们

官方邮箱:service@zsdodo.com

公司地址:北京市丰台区南四环西路188号总部基地三区国联股份数字经济总部
关注我们

公众号

视频号
◎2025 北京智算多多科技有限公司版权所有 京ICP备 2025150592号-1  京公网安备11010602202532号
京公网安备11010602202532号
京公网安备11010602202532号 “Gemini”一词源自拉丁语,意为“双子座”,象征着Google两大顶尖研究团队——Google Brain与DeepMind的合并。这一命名不仅是组织层面的象征,更暗示了模型的技术哲学:让不同类型的数据在同一架构中实现深度融合。
Gemini项目的核心理念是原生多模态(Native Multimodality)。与许多将多模态能力叠加在文本基础之上的前代模型不同,Gemini从设计之初就追求“同时理解、操作和组合不同类型的信息”。Gemini 1.0的技术报告明确确认,模型是“在图像、音频、视频和文本数据上联合训练”的。
Gemini架构基于早期融合(Early Fusion)概念。图像像素块、视频时序帧、音频图谱和文本令牌被投射到统一的潜在空间中。Gemini 2.5技术报告将这一方法描述为“统一多模态令牌交错”(Unified Multimodal Token Interleaving)。
由于所有模态的令牌在共享序列中处理,标准自注意力机制自然地在每一层实现跨模态数据整合。音频信号由专用编码器直接从原始波形处理,保留了使用中间语音转文字系统时会丢失的声学特征——语调、音色、背景噪声。
Gemini 1.0使用的是稠密Transformer架构。从Gemini 1.5开始,模型全面转向稀疏专家混合(Sparse Mixture-of-Experts)架构。这一转变在1.5版技术报告中有明确描述:“这是Gemini 1.5系列的首次发布……采用了新颖的专家混合架构。”
在MoE架构中,标准的前馈网络层被一组专门的子网络——“专家”所取代。对于每个输入令牌,模型仅激活k个专家(k远小于专家总数E),输出为各专家输出的加权和:
y=∑i∈Tk(x)gi(x)Ei(x)
这种方法显著增加了模型的总参数容量,同时保持较低的计算开销,因为每个令牌仅激活参数的一个子集。Google未披露Gemini模型的具体参数数量,但业界普遍认为Gemini Ultra版本的参数量达到万亿级。
这一架构转变带来的直接收益是:Gemini 1.5 Pro以更低的成本实现了与1.0 Ultra相当的质量。稀疏化设计使模型能够在保持推理效率的同时,持续扩展参数容量。
Gemini 1.5实现了突破性进展,将上下文窗口扩展到生产模式下的100万个令牌(实验性测试可达1000万个)。这比当时的竞品(如GPT-4 Turbo的128K令牌)高出一个数量级。
Google报告在100万令牌上下文长度下的“大海捞针”测试中取得了99%的成绩。这一能力使模型能够:
后续世代的Gemini持续扩展上下文能力:
从Gemini 2.5开始,Google正式引入思考模型(thinking model)概念,将“思考”定义为一种独立的运行模式。官方文档将其描述为“改善多步规划和推理的内部计算过程”。
2.5版本及后续模型能够在给出最终答案之前,内部生成和评估中间推理步骤。这显著提高了复杂逻辑和数学任务的准确性。在关键基准测试中:
Gemini的推理机制包含两个层次:
Gemini 3.1 Pro引入了三层思考模式(Low/Medium/High),本质上是“计算-质量-成本”三角关系的显式化管理:
这种设计让用户能够根据任务难度主动权衡成本,而非被动接受统一计价。
从Gemini 2.0开始,Google明确将模型定位为面向“新智能体时代”(agentic era)的模型,具有原生工具使用支持。模型能够与外部世界交互:调用工具、执行Google搜索、运行代码和控制UI元素。
截至2026年2月,Gemini API包含一个正式建立的智能体能力层,支持以下工具:
Gemini 2.5 Pro的“Computer Use Preview”变体(2025年10月发布)进一步强化了智能体操作计算机的能力。这一能力使AI Agent能够通过屏幕截图理解GUI界面,执行点击、输入、拖拽等操作,无需依赖API或HTML解析。
2026年3月,Google发布了首个原生多模态嵌入模型Gemini Embedding 2,这是Gemini技术路线上的又一里程碑。该模型将文本、图像、视频、音频和PDF文档全部映射到同一个向量空间中,实现了真正的“全模态语义对齐”。
各模态的输入规格:
Gemini Embedding 2原生支持交错输入模式,允许在一次请求中同时传入多种模态(如图片+文字),模型会将其理解为一个整体,输出融合了跨模态语义的统一向量。这使AI能够捕捉不同媒体类型之间的复杂关联,例如用一段文字搜索相关的图片,或用一张图片找到含义相似的音频片段。
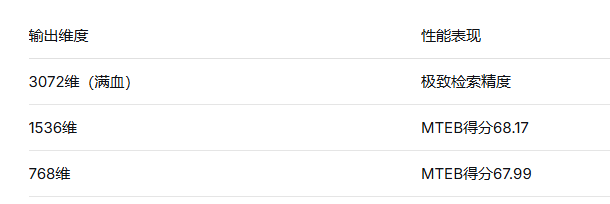
Gemini Embedding 2继续采用Matryoshka Representation Learning(MRL)技术,强制模型将核心语义特征压缩在向量的前几维中。默认输出3072维向量,但开发者可以根据存储预算灵活缩减维度。
回顾Gemini两年多的演进历程,其技术路线呈现出清晰的脉络:
Gemini的技术演进揭示了一个重要趋势:大模型的竞争已从单一的“能力比拼”转向“架构-推理-智能体-嵌入”的全栈竞争。Google凭借芯片从(TPU)到模型(Gemini)再到云平台(Vertex AI)的完整技术栈,正在构建AI时代的基础设施护城河。
对于国内AI爱好者和开发者,通过kula等聚合平台可以零门槛体验Gemini系列模型的完整能力,包括多模态理解、超长文本处理、思考模式等,每日免费额度足以满足日常使用需求。
 智算多多
智算多多官方邮箱:service@zsdodo.com
公司地址:北京市丰台区南四环西路188号总部基地三区国联股份数字经济总部
京公网安备11010602202532号